
24. Data(六)-Spring Data JDBC 详解
24. Data(六)-Spring Data JDBC 详解
前言
Spring Data JDBC 项目将核心 Spring 概念应用到与领域驱动设计原则一致的使用 JDBC 数据库的解决方案的开发中。提供了一个“模板”作为存储和查询聚合的高级抽象。
一、Spring Boot 依赖管理
当必要的依赖项位于类路径上时,Spring Boot 将自动配置 Spring Data 的 JDBC 存储库。它们可以通过spring-boot-starter-data-jdbc的单一依赖项添加到项目中。如果有必要,你可以通过向你的应用程序添加@EnableJdbcRepositories注解或JdbcConfiguration子类来控制 Spring Data JDBC 的配置。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
二、使用 Spring Data Repository
Spring Data Repository 抽象的目标是显著减少为各种持久性存储实现数据访问层所需的样板代码数量。
1.核心概念
Spring Data Repository 抽象的中心接口是Repository。它需要实体类以及实体类的ID类型作为类型参数。 此接口主要用作标记接口,以捕获要使用的类型,并帮助你发现扩展此类型的接口。 CrudRepository和ListCrudRepository接口为被管理的实体类提供了复杂的CRUD功能。
public interface CrudRepository<T, ID> extends Repository<T, ID> {
//存储指定的实体
<S extends T> S save(S entity);
//根据主键查询实体
Optional<T> findById(ID primaryKey);
//查询所有实体
Iterable<T> findAll();
//返回实体数量
long count();
//删除指定实体
void delete(T entity);
//判断给定主键的id,实体存不存在
boolean existsById(ID primaryKey);
}
ListCrudRepository提供了等价的方法,但是它们返回List,而CrudRepository方法返回一个Iterable。
除了 CrudRepository 之外,还有一个 PagingAndSortingRepository 抽象,它添加了额外的方法来简化对实体的分页访问:
public interface PagingAndSortingRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
要访问User的第二个页数据,每页数据量大小为 20,你可以这样做:
PagingAndSortingRepository<User, Long> repository = // … get access to a bean
Page<User> users = repository.findAll(PageRequest.of(1, 20));
除了查询方法之外,还提供计数和删除查询的查询派生。下面的列表显示了派生计数查询的接口定义:
interface UserRepository extends CrudRepository<User, Long> {
long countByLastname(String lastname);
}
下面的展示了派生的删除查询的接口定义:
interface UserRepository extends CrudRepository<User, Long> {
long deleteByLastname(String lastname);
List<User> removeByLastname(String lastname);
}
2.查询方法
标准 CRUD 功能Repository通常对底层数据存储库进行查询。使用 Spring Data,声明这些查询就变成了一个四步过程:
1、 声明扩展Repository或其子接口之一的接口:;
interface PersonRepository extends Repository<Person, Long> {
… }
1、 在接口上声明查询方法;
interface PersonRepository extends Repository<Person, Long> {
List<Person> findByLastname(String lastname);
}
1、 设置 Spring,使用 JavaConfig 或 XML 配置为这些接口创建代理实例(SpringBoot 环境下自动配置);
2、 注入Repository实例并使用它;
class SomeClient {
private final PersonRepository repository;
SomeClient(PersonRepository repository) {
this.repository = repository;
}
void doSomething() {
List<Person> persons = repository.findByLastname("Matthews");
}
}
3.定义 Repository 接口
要定义Repository接口,首先需要定义特定于实体类的Repository接口, 接口必须扩展Repository。如果你想要公开该实体类型的CRUD方法,你可以扩展CrudRepository,或者它的一个变体,而不是Repository。
调整 Repository 定义
Repository定义有多种方式,典型的方法是扩展CrudRepository,这为你提供了 CRUD 功能的方法。 CRUD 表示创建、读取、更新、删除。ListCrudRepository提供了等价的方法,但是它们返回List。
如果你使用的是响应式存储,你可以选择ReactiveCrudRepository,或者RxJava3CrudRepository,这取决于你使用的是哪种响应式框架。
如果你正在使用Kotlin,你可以选择使用Kotlin的协程的CoroutineCrudRepository。
另外,你可以扩展PagingAndSortingRepository, ReactiveSortingRepository, RxJava3SortingRepository,或者CoroutineSortingRepository
如果需要指定Sort抽象或在第一种情况下指定Pageable抽象的方法。
如果你不想扩展 Spring Data 接口,你还可以使用@RepositoryDefinition对Repository接口进行注解。
@RepositoryDefinition(domainClass = Student.class, idClass = Integer.class)
public interface StudentRepository {
Student findById(Integer id);
}
如果应用程序中的许多Repository 都有相同的方法集,那么你可以定义自己的基础接口来继承。这样的接口必须使用@NoRepositoryBean进行注解。这可以防止 Spring Data 尝试直接创建它的实例而失败,因为它不能确定该Repository的实体,因为它包含一个泛型类型变量。
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
interface UserRepository extends MyBaseRepository<User, Long> {
User findByEmailAddress(EmailAddress emailAddress);
}
多个 Spring Data 模块的 Repository
在应用程序中使用惟一的 Spring Data 模块可以使事情变得简单,因为定义范围中的所有Repository接口都绑定到 Spring Data 模块。有时,应用程序需要使用多个 Spring Data 模块。在这种情况下,Repository定义必须区分持久性技术。当 Spring Data 在类路径上检测到多个Repository工厂时,它将进入严格的Repository配置模式。严格配置使用Repository或实体类的细节来决定Repository定义的 Spring Data 模块绑定:
1、 如果Repository定义扩展了特定于模块的Repository接口,那么它是特定 SpringData 模块的有效候选;
interface MyRepository extends JpaRepository<User, Long> {
}
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends JpaRepository<T, ID> {
… }
interface UserRepository extends MyBaseRepository<User, Long> {
… }
MyRepository和UserRepository都是继承的JpaRepository。它们是 Spring Data JPA 模块的有效候选对象。
interface AmbiguousRepository extends Repository<User, Long> {
… }
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends CrudRepository<T, ID> {
… }
interface AmbiguousUserRepository extends MyBaseRepository<User, Long> {
… }
AmbiguousRepository和AmbiguousUserRepository在他们的类型层次结构中只扩展了Repository和CrudRepository。虽然在使用唯一的 Spring Data 模块时这是可以的,但是多个模块不能区分这些存储库应该绑定到哪个特定的 Spring Data。
1、 如果实体类是用特定于模块的类型注解标注的,那么它是特定 SpringData 模块的有效候选对象 SpringData 模块接受第三方注解(如 JPA 的@Entity)或提供自己的注释(如 SpringDataMongoDB 和 SpringDataElasticsearch 中的@Document);
interface PersonRepository extends Repository<Person, Long> {
… }
@Entity
class Person {
… }
interface UserRepository extends Repository<User, Long> {
… }
@Document
class User {
… }
PersonRepository引用Person,Person是用 JPA@Entity注解的,因此这个 Repository 显然属于 Spring Data JPA。UserRepository引用了User,它是用 Spring Data MongoDB 的@Document注解的。
下面这个混乱的例子:
interface JpaPersonRepository extends Repository<Person, Long> {
… }
interface MongoDBPersonRepository extends Repository<Person, Long> {
… }
@Entity
@Document
class Person {
… }
这个示例显示了一个使用 JPA 和 Spring Data MongoDB 注解的实体类。它定义了两个
Repository,JpaPersonRepository和MongoDBPersonRepository。一个用于 JPA,另一个用于 MongoDB。Spring Data 不再能够区分Repository,这导致了未定义的行为。
区分Repository的最后一种方法是限定Repository基础包的范围。基本包定义了扫描 Repository 接口定义的起点,这意味着将Repository定义置于适当的包中。
@EnableJpaRepositories(basePackages = "com.acme.repositories.jpa")
@EnableMongoRepositories(basePackages = "com.acme.repositories.mongo")
class Configuration {
… }
4.定义查询方法
Repository代理有两种方法从方法名派生特定存储的查询:
- 通过直接从方法名派生查询
- 通过使用手动声明的查询
查询查找策略
Repository基础设施可以使用以下策略来解析查询。使用 XML 配置,你可以通过query-lookup-strategy属性在命名空间配置策略。 对于 Java 配置,你可以使用Enable${store}Repositories注解的queryLookupStrategy属性(例如@EnableJdbcRepositories()。某些策略可能不支持特定的数据存储。
queryLookupStrategy可选值为QueryLookupStrategy.Key枚举:CREATE, USE_DECLARED_QUERY, CREATE_IF_NOT_FOUND。
- CREATE:尝试从查询方法名称构造一个特定于存储的查询。 一般的方法是从方法名中删除一组已知的前缀,然后解析方法的其余部分(例如 findByName(),删除已知前缀 findBy)。
- USE_DECLARED_QUERY:尝试查找声明的查询,如果找不到,则抛出异常。 查询可以通过某处的注解定义,也可以通过其他方式声明。
- CREATE_IF_NOT_FOUND: (默认)结合 CREATE 和 USE_DECLARED_QUERY。 它首先查找已声明的查询,如果没有找到已声明的查询,则创建一个基于方法名的自定义查询。
创建查询
从方法名创建查询
interface PersonRepository extends Repository<Person, Long> {
List<Person> findByEmailAddressAndLastname(EmailAddress emailAddress, String lastname);
// 为查询启用distinct标志
List<Person> findDistinctPeopleByLastnameOrFirstname(String lastname, String firstname);
List<Person> findPeopleDistinctByLastnameOrFirstname(String lastname, String firstname);
// 为单个属性启用忽略大小写
List<Person> findByLastnameIgnoreCase(String lastname);
//为所有合适的属性启用忽略大小写
List<Person> findByLastnameAndFirstnameAllIgnoreCase(String lastname, String firstname);
// 为查询启用静态ORDER BY
List<Person> findByLastnameOrderByFirstnameAsc(String lastname);
List<Person> findByLastnameOrderByFirstnameDesc(String lastname);
}
解析查询方法名称分为主语和谓语。 第一部分(find…By, exists…By)定义查询的主语,第二部分构成谓词。 引入子句(主语)可以包含更多的表达式。 find(或其他引入关键字)和By之间的任何文本都被认为是描述性的,除非使用其中一个限制结果的关键字,例如Distinct在要创建的查询上设置一个不同的标志,或者Top/First限制查询结果。
支持查询方法主语关键字
| 关键字 | 描述 |
|---|---|
find…By, read…By, get…By, query…By, search…By, stream…By | 一般查询方法通常返回存储库类型、Collection或Streamable子类型或结果包装器(如Page、GeoResults或任何其他特定于存储的结果包装器)。可以作为findBy…,findMyDomainTypeBy…或与其他关键字组合使用。 |
exists…By | 存在投影,通常返回一个boolean结果。 |
count…By | 统计投影返回一个数字结果。 |
delete…By, remove…By | 删除方法,返回没有结果(void)或删除数量。 |
…First<number>…, …Top<number>… | 将查询结果限制为最先 <number>条结果。这个关键字可以出现在主语的任何位置,在find(和其他关键字)和by之间。 |
…Distinct… | 去重查询只返回唯一结果,这个关键字可以出现在主语的任何位置,在find(和其他关键字)和by之间。 |
支持查询方法谓语关键字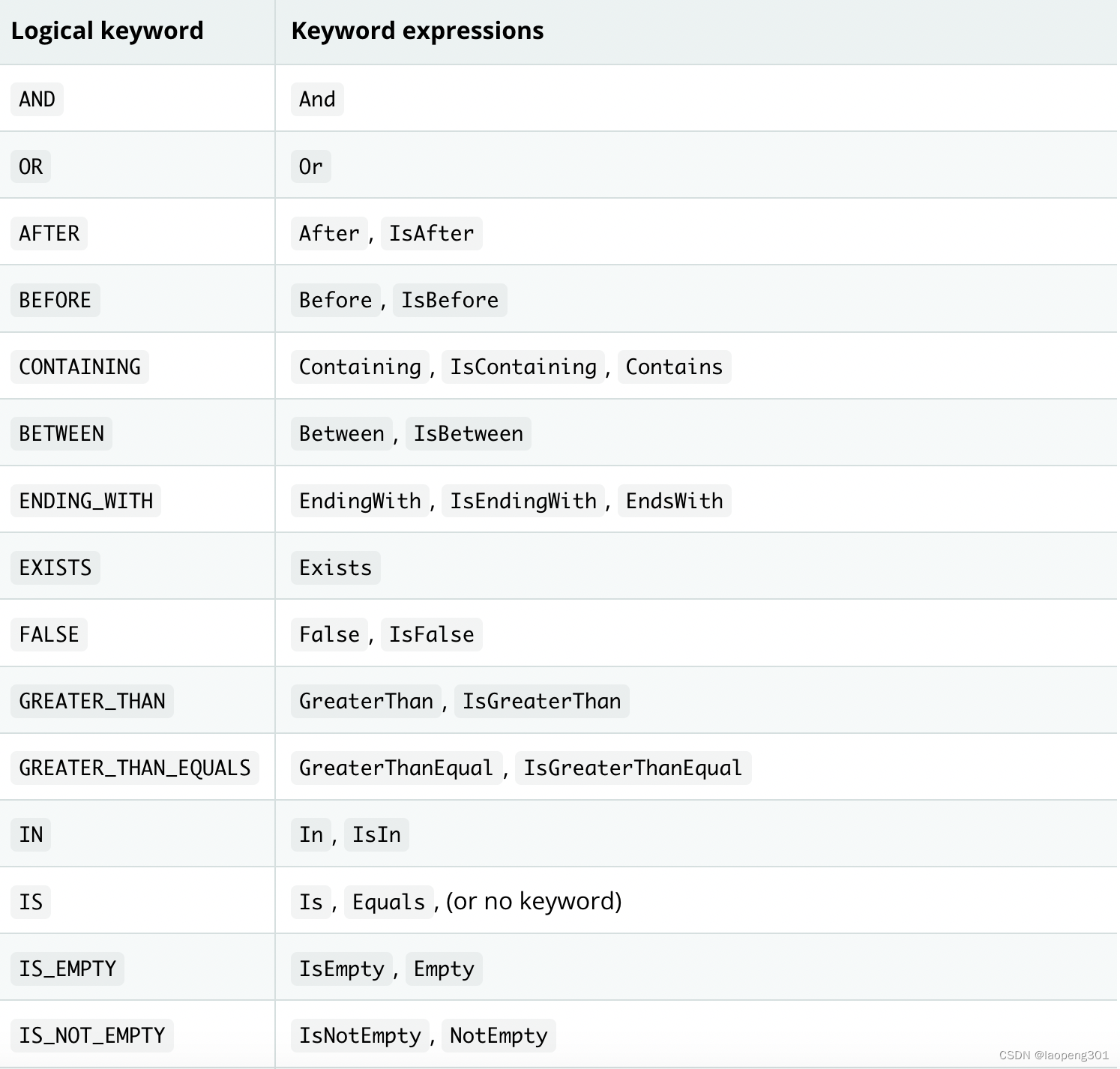
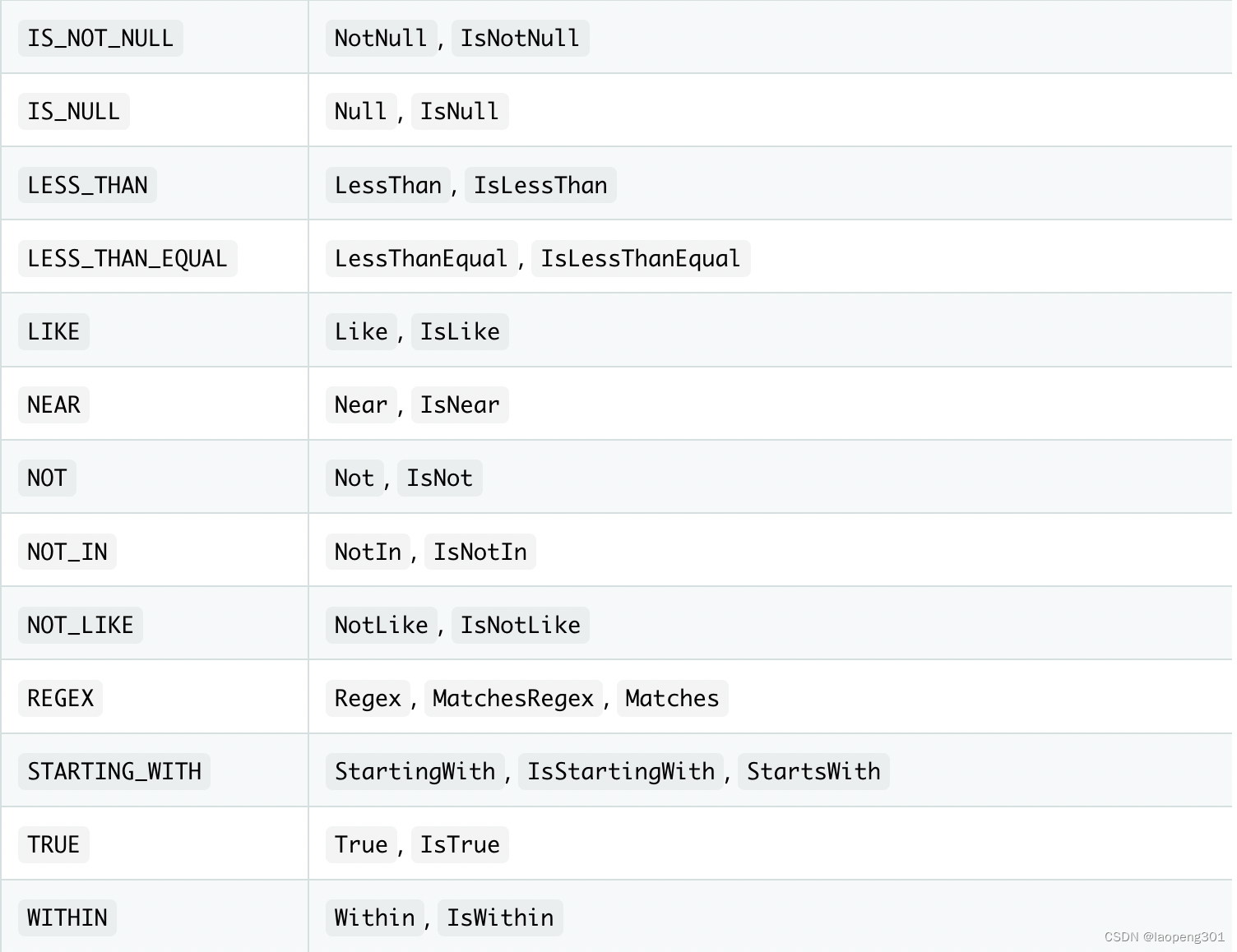
除了过滤器谓词,还支持以下谓词修饰关键字:
| 关键词 | 描述 |
|---|---|
IgnoreCase, IgnoringCase | 与谓词关键字一起使用,用于不区分大小写的比较。 |
AllIgnoreCase, AllIgnoringCase | 忽略所有合适属性的情况。在查询方法谓词中的某处使用。 |
OrderBy… | 指定一个静态排序顺序,后面跟着属性路径和方向(例如OrderByFirstnameAscLastnameDesc)。 |
上述关键字可能因数据存储而异,不是所有的都适用,需要查看具体的数据存储对应的文档。
属性表达式
属性表达式只能引用托管实体的直接属性。 在查询创建时,你已经确保了解析的属性是托管域类的属性。 但是,你也可以通过遍历嵌套属性来定义约束。
List<Person> findByAddressZipCode(ZipCode zipCode);
假设Person对象有一个Address属性,Address对象有一个ZipCode属性。在这种情况下,上述方法创建x.address.zipCode属性遍历。
解析算法首先将整个部分(AddressZipCode)解释为属性,并检查域类中是否有该名称(非大写)的属性。如果算法成功,它就使用该属性。
如果不是,算法将骆驼式部分的源从右侧分割为头和尾,并试图找到相应的属性-在这个例子中,AddressZip 和 Code。 如果算法找到了一个有头部的属性,它会取尾部,然后从那里继续构建树,用刚才描述的方式将尾部向上分割。 如果第一个拆分不匹配,算法将拆分点向左移动(Address, ZipCode)并继续。
虽然这在大多数情况下都是可行的,但是算法可能会选择错误的属性。假设Person类也有一个addressZip属性。
算法会在第一轮分割中匹配,选择错误的属性,然后失败(因为addressZip类型可能没有code属性)。
要解决这种模糊性,可以在方法名中使用_来手动定义遍历点。所以我们的方法名如下:
List<Person> findByAddress_ZipCode(ZipCode zipCode);
因为我们将下划线字符视为保留字符,所以我们强烈建议遵循标准的 Java 命名约定(即,在属性名称中不使用下划线,而是使用驼峰大小写)。
特殊参数处理
要处理查询中的参数,请按照前面的示例定义方法参数。除此之外,基础设施还可以识别某些特定的类型,如Pageable和Sort,以便对查询动态地应用分页和排序。下面的例子演示了这些特性:
Page<User> findByLastname(String lastname, Pageable pageable);
Slice<User> findByLastname(String lastname, Pageable pageable);
List<User> findByLastname(String lastname, Sort sort);
List<User> findByLastname(String lastname, Pageable pageable);
第一个方法允许你向查询方法传递org.springframework.data.domain.Pageable实例,以便将分页动态添加到静态定义的查询中。Page知道可用的元素和页的总数。它通过基础设施触发一个count查询来计算总体数量来实现这一点。因为这可能很昂贵(取决于使用的存储),所以可以返回一个Slice。Slice只知道下一个Slice是否可用,当遍历较大的结果集时,这可能就足够了。
排序选项也可以通过Pageable实例处理。如果你只需要排序,添加org.springframework.data.domain.Sort参数到你的方法中。如你所见,返回List也是可能的。在本例中,没有创建构建实际Page实例所需的额外元数据(反过来,这意味着没有发出必要的额外count查询)。相反,它将查询限制为只查找给定范围的实体。
分页和排序
可以使用属性名定义简单的排序表达式。可以将表达式连接起来,以将多个条件收集到一个表达式中。
排序:
Sort sort = Sort.by("firstname").ascending()
.and(Sort.by("lastname").descending());
...order by firstname asc,lastname desc;
对于定义排序表达式的类型安全的方法,从定义排序表达式的类型开始,并使用方法引用来定义要排序的属性。
TypedSort<Person> person = Sort.sort(Person.class);
Sort sort = person.by(Person::getFirstname).ascending()
.and(person.by(Person::getLastname).descending());
TypedSort.by(…)使用运行时代理(通常)使用CGlib,这可能会干扰本地映像编译时使用工具,如Graal VM native。
限制查询结果
可以通过使用first或top关键字限制查询方法的结果,这两个关键字可以互换使用。可以在top或first后面追加一个可选的数值,以指定要返回的最大结果大小。如果省略了该数字,则假定结果大小为1。下面的例子展示了如何限制查询大小:
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
Slice<User> findTop3ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);
限制表达式还支持Distinct关键字,用于支持去重查询的数据存储。此外,对于将结果集限制为一个实例的查询,支持使用Optional关键字将结果包装。
Repository 方法返回集合或可迭代对象
返回多个结果的查询方法可以使用标准的 Java Iterable、List和Set。除此之外,我们还支持返回 Spring Data 的Streamable(可迭代对象的自定义扩展),以及Vavr提供的集合类型。
Streamable 作为查询方法返回类型
您可以使用 Streamable 替代 Iterable 或任何集合类型。它提供了方便的方法来访问非并行的 Stream (Iterable 中没有),以及直接在元素上…filter(…)和…map(…)的能力,并将 Streamable 连接到其他元素:
interface PersonRepository extends Repository<Person, Long> {
Streamable<Person> findByFirstnameContaining(String firstname);
Streamable<Person> findByLastnameContaining(String lastname);
}
Streamable<Person> result = repository.findByFirstnameContaining("av")
.and(repository.findByLastnameContaining("ea"));
返回自定义的 Streamable 包装类型
为集合提供专用的包装器类型是一种常用的模式,可为返回多个元素的查询结果提供 API。通常,通过调用返回类集合类型的存储库方法并手动创建包装器类型的实例来使用这些类型,你可以避免额外的步骤,因为 Spring Data 允许你使用这些包装类型作为查询方法的返回类型,如果它们满足以下条件:
1、 该类型实现了 Streamable;
2、 该类型公开了一个构造函数或一个名为 of(…)或 valueOf(…)的静态工厂方法,该方法接受 Streamable 作为参数;
//一个产品实体,它公开API以访问产品的价格。
class Product {
MonetaryAmount getPrice() {
… }
}
@RequiredArgsConstructor(staticName = "of")
/**
用于Streamable<Product>的包装器类型,可以使用Products.of(…)(使用Lombok注释创建的工厂方法)来构造。 接受Streamable<Product>的标准构造函数也可以。
**/
class Products implements Streamable<Product> {
private final Streamable<Product> streamable;
//包装器类型公开一个额外的API,在Streamable<Product>上计算新值
public MonetaryAmount getTotal() {
return streamable.stream()
.map(Priced::getPrice)
.reduce(Money.of(0), MonetaryAmount::add);
}
//实现Streamable接口并委托给实际结果。
@Override
public Iterator<Product> iterator() {
return streamable.iterator();
}
}
//包装器类型Products可以直接用作查询方法返回类型。 你不需要返回Streamable<Product>并在存储库client中的查询之后手动包装它。
interface ProductRepository implements Repository<Product, Long> {
Products findAllByDescriptionContaining(String text);
}
Repository 方法的 Null 处理
从 Spring Data 2.0 开始,返回单个聚合实例的存储库 CRUD 方法使用 Java 8 的Optional来指示可能没有值。除此之外,Spring Data 还支持在查询方法上返回以下包装器类型:
- com.google.common.base.Optional
- scala.Option
- io.vavr.control.Option
可空性注解
你可以使用 Spring Framework 的可空性注解来表示存储库方法的可空性约束。它们提供了一种工具友好的方法和在运行时可选择的空检查,如下:
@NonNullApi: 用于包级别,分别声明参数和返回值的默认行为既不接受也不产生空值。
@NonNull: 用于不能为空的参数或返回值 ( 在@NonNullApi 应用的参数和返回值上不需要).
@Nullable: 用于可为空的参数或返回值。
Spring 注释是用 JSR 305 注解(一个暂停但广泛使用的JSR)进行元注解的。JSR 305 元注解允许工具供应商(如 IDEA、Eclipse 和 Kotlin)以通用的方式提供零安全支持,而不必硬编码对 Spring 注解的支持。为了在运行时检查查询方法的可空性约束,你需要使用 package-info.java 中的 Spring @NonNullApi 来激活包级别的不可空性,如下面的例子所示:
package-info.java
@org.springframework.lang.NonNullApi
package com.acme;
一旦设置了非空缺省值,Repository查询方法调用将在运行时验证可空性约束。如果查询结果违反了定义的约束,则抛出异常。当方法返回null但声明为不可空时(默认情况下,在Repository所在的包上定义注释),就会发生这种情况。如果你想再次选择可为空的结果,可以有选择地在各个方法上使用@Nullable。
//Repository包设置为非空 NonNullApi
package com.acme;
import org.springframework.lang.Nullable;
interface UserRepository extends Repository<User, Long> {
//当查询没有产生结果时抛出EmptyResultDataAccessException。 当传递给方法的emailAddress为空时,抛出一个IllegalArgumentException。
User getByEmailAddress(EmailAddress emailAddress);
//当查询没有产生结果时返回null。 还接受null作为emailAddress的值
@Nullable
User findByEmailAddress(@Nullable EmailAddress emailAdress);
//当查询没有产生结果时返回Optional.empty()。 当传递给方法的emailAddress为空时,抛出一个IllegalArgumentException。
Optional<User> findOptionalByEmailAddress(EmailAddress emailAddress);
}
流式查询结果
通过使用 Java 8 Stream 作为返回类型,你可以逐步地处理查询方法的结果。 不是将查询结果包装在 Stream 中,而是使用特定于数据存储的方法来执行流,如下所示的示例:
@Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream();
Stream<User> readAllByFirstnameNotNull();
@Query("select u from User u")
Stream<User> streamAllPaged(Pageable pageable);
流可能会包装底层特定于数据存储的资源,因此必须在使用后关闭。你可以使用close()方法手动关闭流,或者使用 Java 7 的 try-with-resources块,如下所示:
try (Stream<User> stream = repository.findAllByCustomQueryAndStream()) {
stream.forEach(…);
}
并不是所有 Spring Data 模块目前都支持Stream<T>作为返回类型。
异步查询结果
你可以使用 Spring 的异步方法运行 Repository 查询。这意味着该方法在调用后立即返回,而实际查询发生在已提交给 Spring TaskExecutor 的任务中。
@Async
Future<User> findByFirstname(String firstname);
@Async
CompletableFuture<User> findOneByFirstname(String firstname);
@Async
ListenableFuture<User> findOneByLastname(String lastname);
5.Repository 自定义实现
Spring Data 提供了各种选项来创建查询方法,只需编写少量代码。但是,当这些选项不能满足你的需求时,你还可以为Repository方法提供自己的自定义实现。
1、 自定义repository接口;
interface CustomizedUserRepository {
void someCustomMethod(User user);
}
1、 实现接口;
class CustomizedUserRepositoryImpl implements CustomizedUserRepository {
public void someCustomMethod(User user) {
}
}
与接口相对应的类名中最重要的部分是
Impl后缀。
实现本身不依赖于 Spring Data,可以是一个常规的 Spring bean。因此,你可以使用标准的依赖项注入行为将引用注入到其他bean(例如JdbcTemplate)
3、 与CrudRepository结合;
interface UserRepository extends CrudRepository<User, Long>, CustomizedUserRepository {
// Declare query methods here
}
自定义 Repository 支持多个继承。
interface UserRepository extends CrudRepository<User, Long>, HumanRepository {
// Declare query methods here
}
重写 CrudRepository 方法
interface CustomizedSave<T> {
<S extends T> S save(S entity);
}
class CustomizedSaveImpl<T> implements CustomizedSave<T> {
public <S extends T> S save(S entity) {
// Your custom implementation
}
}
interface UserRepository extends CrudRepository<User, Long>, CustomizedSave<User> {
}
interface PersonRepository extends CrudRepository<Person, Long>, CustomizedSave<Person> {
}
配置
Spring Boot 默认情况下针对 Spring Data JDBC 自动配置 Repository 接口,但是实现类必须后缀名是Impl。
@EnableJdbcRepositories(repositoryImplementationPostfix = "Impl")