
JVM (八) 执行引擎相关内容
JVM (八) 执行引擎相关内容
一:两种解释器
JAVA 字节码解释器:
java 字节码===》c++代码==》硬编码。
首先.java 文件编译成字节码,遍历每行的字节码指令,因为每个字节码指令的含义都是固定的所以可以根据每行字节码指令来转成 c++代码调用,最后转成硬编码(机器码)来执行。
模板解释器:
由 java 字节码==》硬编码。可以从 java 字节码直接到硬编码。
模板解释器底层实现流程:
1)申请一块内存:可读可写可执行
2)将处理 new 字节码的硬编码(举个例子)拿过来,可以通过解析文件得到
3)将处理 new 字节码的硬编码写入申请的内存
4)申请一个函数指针,用这个函数指针执向这块内存
5)调用的时候,直接通过这个函数指针调用就可以了。
Mac 中是无法使用 JIT 的!因为 Mac 无法申请一块可读可写可执行的内存块
二:三种运行模式
-Xint 纯字节码解释器
-Xcomp 纯模板解释器
-Xmixed 字节码解释器+模板解释器
默认是 mixed,可以通过 java -version 查看
混合模式

纯字节码解释器

纯模板解释器:

三:三种运行模式的性能
1:-Xint 纯字节码解释器, 解释一行执行一行,其实属于解释执行了。如果代码多的话肯定效率不会太高。
2:-Xcomp 纯模板解释器,需要把.class 编译成硬编码之后再执行,如果程序很大,启动时间耗时可能会较久。
3:-Xmixed 字节码解释器+模板解释器,所以现在都是混合模式的编译。刚启动的时候采用字节码解释器,这样只要解析执行启动相关的代码即可,等到程序运行一段时间之后,即时编译器收集到的代码越来越多就可以使用模板解释器提高运行效率。
2,3 那个性能比较高,主要看程序的规模了。
四:模板解释器使用的硬编码谁来编译呢?编译后又是放在哪里呢?
即时编译器:属于 JIT 技术。
**1)**C1 即时编译器。
c1 编译器是 client 模式下的即时编译器。现在 64bit 机都是 server 模式了
(1)触发条件比 C2 宽松,需要收集的数据较少。
(2)编译的优化比较浅比如:基本运算在编译的时候运算掉了或这 final 修饰的字符串的优化。
(3)c1 编译器编译生成的代码执行效率比 c2 低些。
就算对其进行调优,性能的提升曲线也很平缓。
2)C2 编译器
c2 编译器是 server 模式下的即时编译器。
(1)触发的条件比较严格,一般来说,程序运行一段时间以后触发。
(2)优化的比较深。比如编译的时候判断操作是否设计到堆栈,如果没有的话直接优化掉了。
(3)编译生成的代码执行效率比 c1 更高。
3)混合编译
jdk6 以前是没有混合编译的,后来根据两种编译器的使用场景组合起来使用进一步提升性能
程序运行初期触发 c1 编译器,程序运行一段之后触发 c2 编译器。
这里说明一点:
字节码解释器是解释执行的,和即时编译器无关。
模板解释器执行的硬编码就是即时编译器编译的。
即时编译触发的条件!
硬编码在 jvm 中称为热点代码。
触发即时编译的最小单位不是一个函数,而是一个代码块(for,while 等)
client 模式下,默认值 1500。即一段代码执行 1500 次会触发即时编译。
server 模式下,默认值是 10000。即一段代码执行 10000 次会触发即时编译。
热度衰减:
有一段代码执行了 7000 次,还有 3001 次触发即时编译,但是在一定时间内,这段代码没有被调用,这个次数会以两倍速递减变成 3500,这时候就需要再执行 6501 次才会触发即时编译。这种就叫热度衰减。
补充知识点!!!!!!!
热机切冷故障。
热机:就是已经运行了一段时间的机器。
冷机:就是刚运行的机器。
问题:
当给已经运行了一段时间的热机集群中增加一个节点冷机的时候,冷机起到负载均衡的作用,但是会出现冷机一上线就会挂掉。
原因:
热机中有热点代码缓存,抗的并发更大,冷机中一边运行程序一边触发即时编译占用 cpu。
解决方案:
冷机切流量,慢慢切,等到触发即时编译了就可以正常负载了。
热点代码缓存区,在方法区。这块也是调优需要调的地方,但是一般不动。
java -XX:+PrintFlagsFinal -version | grep CodeCacheSize
server 编译器模式下代码缓存大小则起始于 2496KB
client 编译器模式下代码缓存大小起始于 160KB
五:即时编译器是如何运行的
即时编译时通过 VM_Thread 线程执行的
1:将即时编译器任务写入队列
2:VM_THREAD 从这个队列中读取任务并执行。
异步执行的。
可以查看编译线程有多少个?如果有必要可以调整这个大小。
java -XX:+PrintFlagsFinal -version | grep CICompilerCount
六:如何理解 java 是半解释半编译型语言
1:javac 编译 java 文件,java 运行
2:字节码解释器解释执行,模板解释器编译执行。
七:逃逸分析
逃逸:对象逃逸,直接解释逃逸不如直接说明不逃逸更直观。逃逸的话,对于对象如果是共享变量,返回值,参数,则对象是逃逸的,就是逃到了线程外,方法外。
对象不逃逸:对象的作用域是局部变量,对象就是不逃逸的。
-XX:+DoEscapeAnalysis//开始逃逸分析 -XX:-DoEscapeAnalysis//禁用
基于逃逸分析,JVM 开发了三种优化技术:
栈上分配:
逃逸分析开启,栈上分配就是存在的,逃逸分析默认是开启的。我们可以测试下看栈上分配的存在。
我们在堆中创建 20 万个对象,如果堆里这个对象少于 20 个,说明有在栈上分配的。前提不会发生 GC。
我们先测试只在堆上创建,我把逃逸分析关闭了。

public static void main(String[] args) {
for (int i = 0; i <200000 ; i++) {
DriverDemo s1= new DriverDemo();
}
while (true);
}
执行之后,我们通过 HSDB 查看堆中创建了多少个对象。**java -cp sa-jdi.jar sun.jvm.hotspot.HSDB 。**首先查找 jvm 线程。在 HSDB 中打开线程 id.
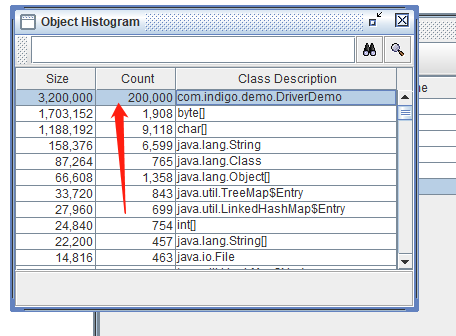
看到堆里有 20 万个对象。说明此时没有发生栈上分配。
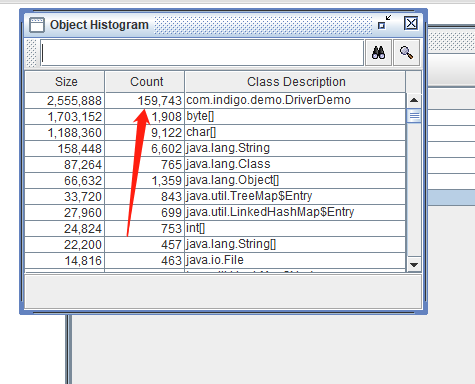
我们把逃逸分析打开再执行查看 HSDB。此时堆中对象已经少于 20 万个了,所以出现了栈上分配。
标量替换:
标量:是不可拆分的变量,java 中的基本数据类型就是标量的。
scalar replacement。Java 中的原始类型无法再分解,可以看作标量(scalar);指向对象的引用也是标量;而对象本身则是聚合量(aggregate),可以包含任意个数的标量。如果把一个 Java 对象拆散,将其成员变量恢复为分散的变量,这就叫做标量替换。拆散后的变量便可以被单独分析与优化,可以各自分别在活动记录(栈帧或寄存器)上分配空间;原本的对象就无需整体分配空间了
聚合量:是可拆分的,就是引用数据类型。
锁消除:
锁消除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行削除。锁削除的主要判定依据来源于逃逸分析的数据支持,如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当作栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。
比如下面这段代码就会在编译的时候把同步锁去掉。
synchronized (new Object()){
System.out.println("ddd");
}