
21. Data(三)-Spring Data JPA 详解
21. Data(三)-Spring Data JPA 详解
一、简介
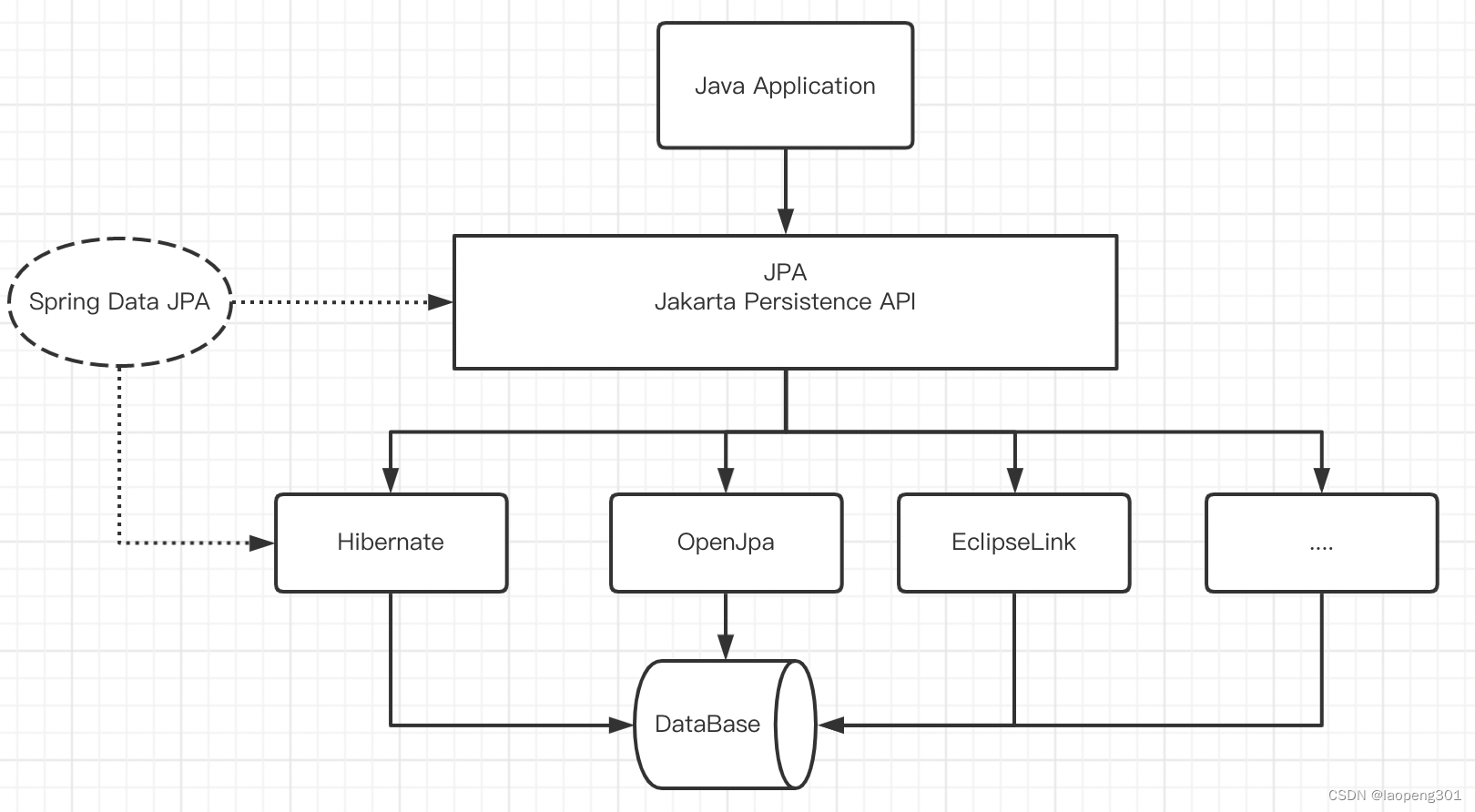
Jakarta Persistence API是一种标准技术,允许你将对象“映射”到关系数据库。
JPA 包括以下 3 方面的内容:
1、 API 标准:在jakarta.persistence的包下面,用来操作实体对象,执行CRUD操作;
2、 面向对象的查询语言:JavaPersistenceQueryLanguage(JPQL);
3、 ORM 映射元数据:JPA 支持 XML 和 JDK5.0 注解两种元数据的形式,元数据描述对象和表之间的映射关系;
Jakarta Persistence 3.0 规范是将项目迁移到 Eclipse Foundation 之后的第一个版本,
javax.*
包移动到jakarta.*包。
JPA 是一套标准接口,目前Hibernate、TopLink 以及OpenJPA都提供了 JPA 实现。
Spring Data JPA为Jakarta Persistence API (JPA)提供存储库支持(底层实现还是基于Hibernate)。它简化了需要访问JPA数据源的应用程序的开发。
spring-boot-starter-data-jpa POM提供了一种快速启动的方法。它提供了以下关键依赖关系:
1、 Hibernate:最流行的JPA实现之一;
2、 SpringDataJPA:帮助你实现基于JPA的存储库;
3、 SpringORM:来自 Spring 框架的核心 ORM 支持;
二、快速使用 JPA 访问数据
1.环境准备
- Java 17及以上版本
- Maven 3.5+
- IntelliJ IDEA 2021.2.1 以及更高版本
1.数据库准备
本文已mysql5.7数据库为例:
DROP TABLE IF EXISTS tb_student;
CREATE TABLE tb_student (
id int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
name varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '姓名',
sex tinyint(1) DEFAULT NULL COMMENT '性别',
age int(11) DEFAULT NULL COMMENT '年龄',
grade varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '年级',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
INSERT INTO tb_student VALUES (1, '张三', 1, 14, '初中');
INSERT INTO tb_student VALUES (2, '李四', 1, 16, '高中');
2.创建项目
1.使用Srping Initializr 新建项目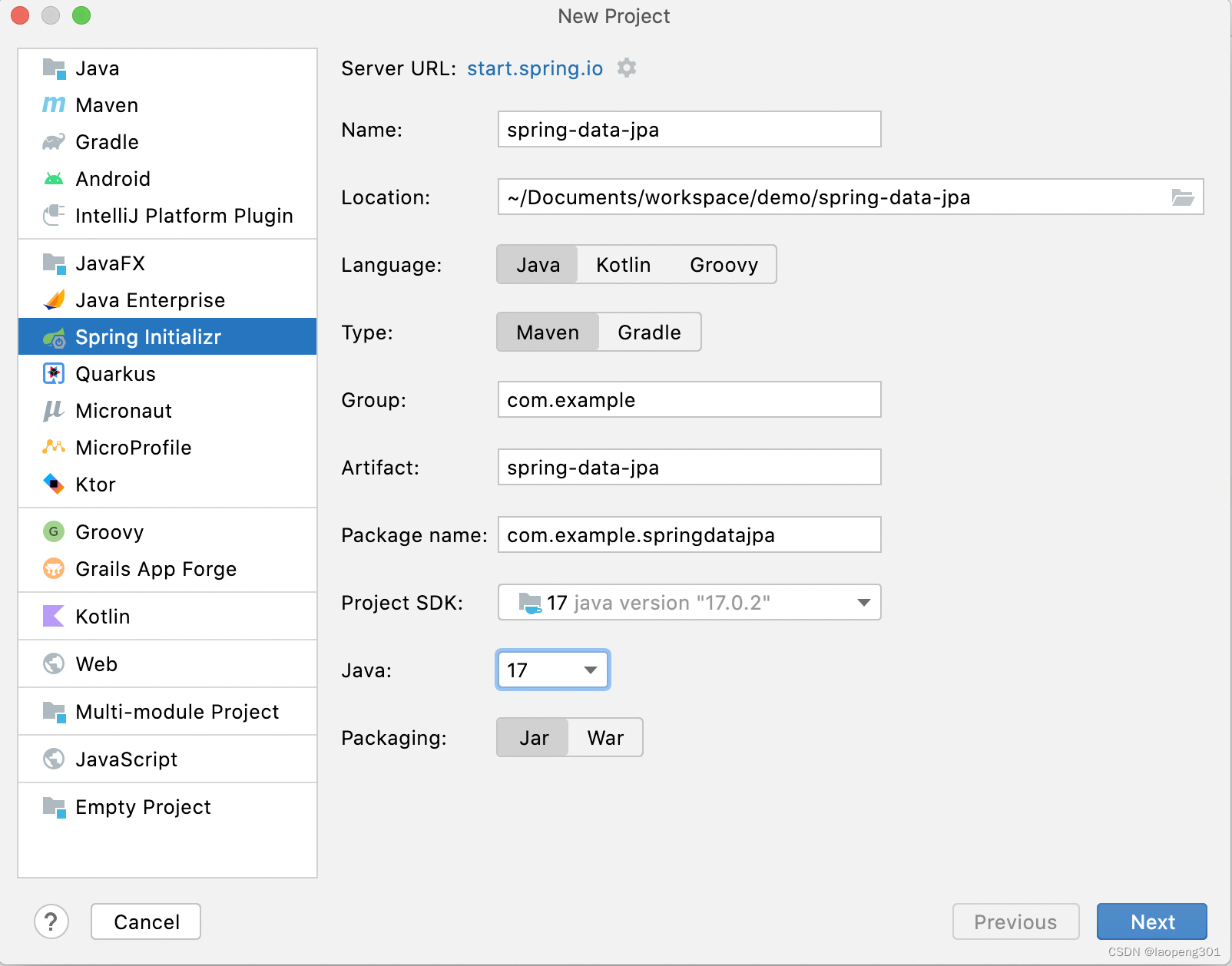
2、 选择依赖SpringDataJPA和Mysql驱动;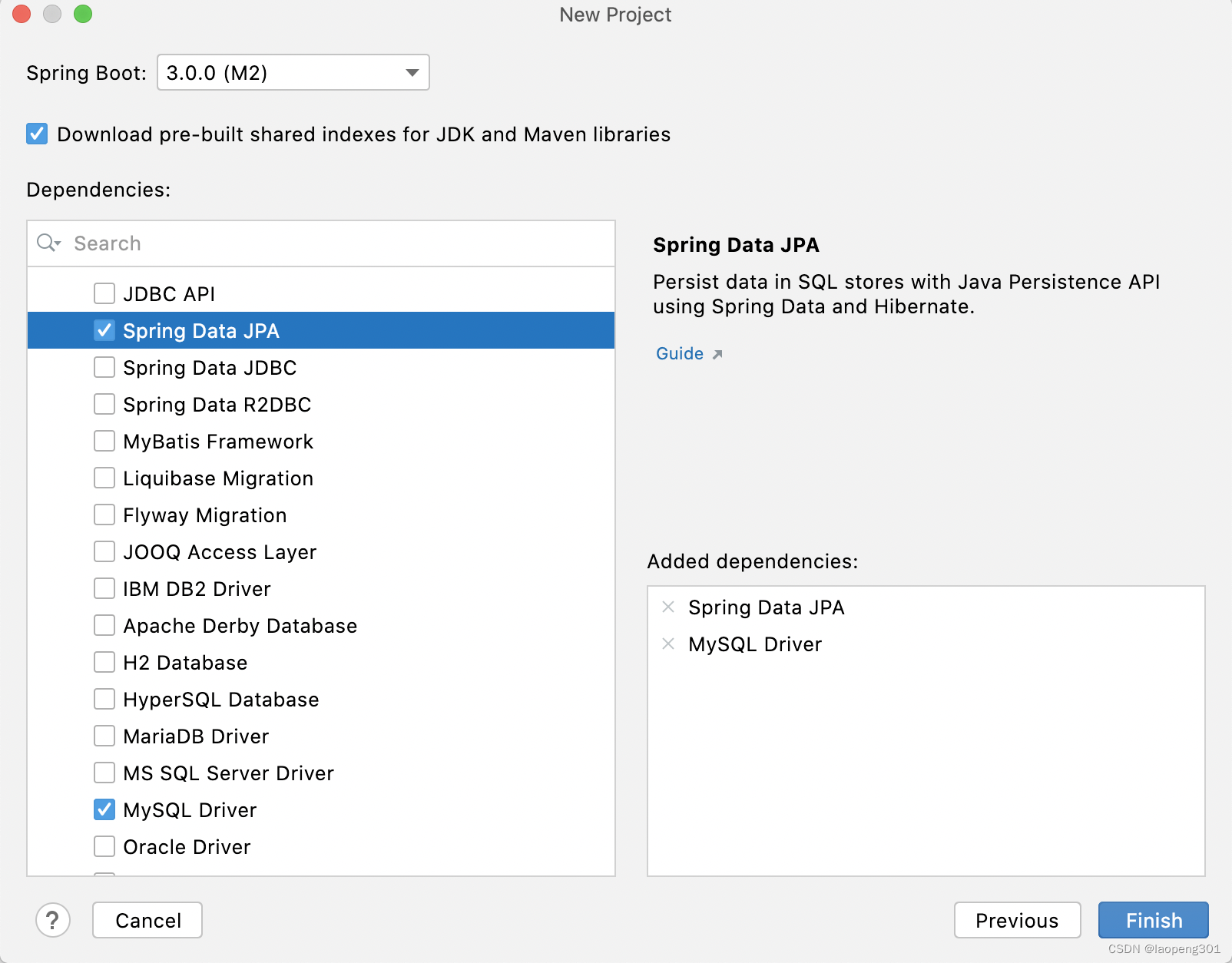
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
3.定义实体
package com.example.springdatajpa.entity;
import jakarta.persistence.*;
import java.io.Serializable;
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private Integer sex;
private Integer age;
private String grade;
public Student(String name, Integer sex, Integer age, String grade) {
this.name = name;
this.sex = sex;
this.age = age;
this.grade = grade;
}
public Student() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGrade() {
return grade;
}
public void setGrade(String grade) {
this.grade = grade;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", sex=" + sex +
", age=" + age +
", grade='" + grade + '\'' +
'}';
}
}
Student类带有@Entity注释,表示它是一个JPA实体。@Table(name = "tb_student")注解表示实体对应数据的表tb_student。Student对象的id属性带有@Id注释,以便JPA将其识别为对象的id。id属性还带有@GeneratedValue(strategy = GenerationType.IDENTITY)注解,表示id生成按照数据库自增主键。其它的字段没有任何的注解,表示字段名称与数据库字段名一致。
4.创建查询
Spring Data JPA 侧重于使用 JPA 在关系数据库中存储数据。它最引人注目的特性是在运行时,从repository接口自动创建存储的能力。
package com.example.springdatajpa.repository;
import com.example.springdatajpa.entity.Student;
import org.springframework.data.repository.CrudRepository;
import java.util.List;
public interface StudentRepository extends CrudRepository<Student, Integer> {
List<Student> findByGrade(String grade);
Student findById(Integer id);
}
StudentRepository继承CrudRepository接口。在CrudRepository中它使用实体和ID的类型,Student和Integer。
通过扩展CrudRepository, StudentRepository继承了几个用于处理客户端持久性的方法,包括用于保存、删除和查找客户实体的方法。
Spring Data JPA 还允许您通过声明其他查询方法的方法签名来定义它们。例如,StudentRepository包含findByGrade()方法。
在典型的 Java 应用程序中,你可能希望编写一个实现StudentRepository的类。
然而,这正是 Spring Data JPA 如此强大的原因:你不需要编写存储库接口的实现。Spring Data JPA 在运行应用程序时创建一个实现。
默认情况下,SpringBoot 启用
JPA Repository支持,并查找@SpringBootApplication所在的包(及其子包)。如果你的配置有位于包中不可见的JPA Repository接口定义,你可以通过使用@EnableJpaRepositories和它的类型安全的basePackageClasses=MyRepository.class参数指出替代包。
5.测试
package com.example.springdatajpa;
import com.example.springdatajpa.entity.Student;
import com.example.springdatajpa.repository.StudentRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import java.util.Optional;
@SpringBootApplication
public class SpringDataJpaApplication {
private Logger logger = LoggerFactory.getLogger(SpringDataJpaApplication.class);
public static void main(String[] args) {
SpringApplication.run(SpringDataJpaApplication.class, args);
}
@Bean
public CommandLineRunner studentTest(StudentRepository studentRepository) {
return args -> {
logger.info("新增一个学生");
studentRepository.save(new Student("小红", 0, 20, "大学"));
logger.info("查询所有学生");
studentRepository.findAll().forEach(s -> {
logger.info(s.toString());
});
logger.info("查询id为1的学生");
Optional<Student> student = studentRepository.findById(1);
logger.info(student.get().toString());
logger.info("查询 grade为大学的所有学生");
studentRepository.findByGrade("大学").forEach(s -> {
logger.info(s.toString());
});
};
}
}
结果:

注解
@Entity
描述
注解在类上,表示为JPA实体类,对应数据库表映射的对象。
属性name:(可选)实体名称。默认为实体类的非限定名称。此名称用于引用查询中的实体。在 Jakarta Persistence 查询语言中,名称不能是保留字面值。
例子
@Entity(name="student")
public class Student {
...}
@Table
描述
当实体类与其映射的数据库表名不同名时需要使用 @Table。
属性name:(可选)表名,默认为实体名称。catalog:(可选)表的 catalog,默认为默认 catalog。schema:(可选)表的 schema,默认为用户的默认 schema。uniqueConstraints:(可选)表上批量设置唯一约束,只有在表生成时才生效。这些约束适用于Column和JoinColumn注解指定的任何约束以及主键映射所包含的约束。indexes:(可选)表的索引,只有在表生成时才生效。注意,没有必要为主键指定索引,因为主键索引将自动创建。
sql环境中Catalog和Schema都属于抽象概念,主要用来解决命名冲突问题。一个数据库系统包含多个Catalog,每个Catalog包含多个Schema,每个Schema包含多个数据库对象(表、视图、字段等)。数据库的完全限定名称可以为 Catalog 名称.Schema 名称.表名称。
例子
@Entity
@Table(name="tb_student", schema="spring-boot-data-learn")
public class Student {
... }
@Column
描述
指定持久化属性字段到数据库列的映射。如果没有指定Column注解,表示属性和数据库字段一致。
属性name:(可选)数据库列名称,默认持久化类属性字段名称。unique:(可选)列是否为唯一键。这是表级别上UniqueConstraints注解的快捷方式,在惟一键约束只对应于单个列时非常有用。这个约束适用于主键映射所包含的任何约束和表级指定的约束。nullable: (可选)数据库列是否能为 null,默认 true。insertable: (可选)SQL INSERT 是否包含该列,默认true。updatable: (可选)SQL UPDATE 是否包含该列,默认true。columnDefinition: (可选)表示创建表时,该字段创建的 SQL 语句,一般用于通过Entity生成表定义时使用,如果数据库中表已经建好,该属性没有必要使用。
table:(可选)表示当映射多个表时,指定表的表中的字段。默认值为主表的表名length: (可选)列长度(仅当 使用字符串值列),默认255。precision:decimal字段长度, 默认0。scale:decimal字段,小数点位数,默认 0。
例子
@Column(name="DESC", nullable=false, length=512)
public String getDescription() {
return description; }
@Column(name="DESC",
columnDefinition="CLOB NOT NULL",
table="EMP_DETAIL")
@Lob
public String getDescription() {
return description; }
@Column(name="ORDER_COST", updatable=false, precision=12, scale=2)
public BigDecimal getCost() {
return cost; }
@Id
描述
指定实体主键,应用Id注解的字段或属性应该是以下类型之一:
- 任何 Java 基本类型
- 任何包装类型
- 字符串
- java.util.Date
- java.sql.Date
java.math.BigDecimal
java.math.BigInteger
假如实体的主键的映射列是表的主键。如果没有指定Column注释,则主键列名是@Id 注解的字段名称。
属性
无
例子
@Id
public Long getId() {
return id; }
@GeneratedValue
描述
提供主键值的生成策略的说明。GeneratedValue注解可以与Id注解一起应用于实体或映射超类的主键属性或字段。只需要对简单的主键支持GeneratedValue注解的使用。派生主键不支持使用GeneratedValue注释。
属性strategy: (可选)主键生成策略,持久性提供者必须使用该策略来生成带注解的实体主键,默认GenerationType.AUTO,生成策略支持如下:
1、 GenerationType.TABLE:通过数据库表生成主键;
2、 GenerationType.SEQUENCE:使用数据库序列为实体分配主键;
3、 GenerationType.IDENTITY:使用数据库ID自增长为实体分配主键;
4、 GenerationType.AUTO:JPA为特定数据库选择适当的策略(默认);
generator:(可选)在SequenceGenerator或TableGenerator注解中指定的主键生成器的名称。
例子
@Id
@GeneratedValue(strategy=SEQUENCE, generator="CUST_SEQ")
@Column(name="CUST_ID")
public Long getId() {
return id; }
@Id
@GeneratedValue(strategy=TABLE, generator="CUST_GEN")
@Column(name="CUST_ID")
Long id;
Spring Boot 中如果主键是数据库自增的(
auto_increment),@GeneratedValue需要设置参数,@GeneratedValue(strategy = GenerationType.IDENTITY)
@IdClass
描述
指定映射到实体的多个字段的联合主键类。主键类中的字段或属性的名称必须与实体的主键字段对应,且类型必须相同。
属性value:主键类
例子
public class EmployeePK{
String empName;
Date birthDay;
}
@IdClass(com.acme.EmployeePK.class)
@Entity
public class Employee {
@Id String empName;
@Id Date birthDay;
...
}
@Basic
描述
到数据库列的最简单映射类型。Basic注解可以应用于以下任何类型的持久属性或实例变量:Java 原生类型、原生类型的包装器、String, java.math.BigInteger, java.math.BigDecimal, java.util.Date, java.util.Calendar, java.sql.Date, java.sql.Time, java.sql.Timestamp, byte[], Byte[], char[], Character[], enums,,以及实现java.io.Serializable的任何其他类型。
对于这些类型的持久字段和属性,Basic注释的使用是可选的。如果没有为这样的字段或属性指定Basic注解,则将应用Basic注解的默认值(@Basic(fetch = FetchType.EAGER,optional = true))。
属性fetch:表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主动获取和延迟加载,默认为 EAGER。optional:表示该属性是否允许为null, 默认为true。
例子
@Basic
protected String name;
@Basic(fetch=LAZY)
protected String getName() {
return name; }
@Transient
描述
指定属性或字段不是持久的。它应用于由@Entity 、@MappedSuperclass、@Embeddable注解类的属性或字段。
属性
无
例子
@Entity
public class Employee {
@Id int id;
@Transient User currentUser;
...
}
@Enumerated
描述
指定持久属性或字段作为枚举类型持久保存。如果实体中枚举类型,未指定 @Enumerated注解,则EnumType值为ORDINAL,映射时的序号是从0开始的。
属性
无
例子
public enum EmployeeStatus {
FULL_TIME, PART_TIME, CONTRACT}
public enum SalaryRate {
JUNIOR, SENIOR, MANAGER, EXECUTIVE}
@Entity public class Employee {
public EmployeeStatus getStatus() {
...}
...
@Enumerated(STRING)
public SalaryRate getPayScale() {
...}
...
}
上述例子中 EmployeeStatus 未指定
@Enumerated注解,JPA 持久化时插入数据库的值FULL_TIME:0,PART_TIME:1,CONTRACT:2。
@MappedSuperclass
描述
指定一个类,该类的映射信息应用于从其继承的实体。映射超类没有为其定义单独的表。
用MappedSuperclass注解指定的类可以以与实体相同的方式进行映射,只是映射将只应用于它的子类,因为映射的超类本身不存在表。当应用于子类时,继承的映射将应用于子类表的上下文中。映射信息可以通过使用AttributeOverride和AssociationOverride注解或相应的XML元素在这些子类中重写。
使用场景常见的可以定义自己的AbstractEntity。
属性
无
例子
@MappedSuperclass
public class Employee {
@Id protected Integer empId;
@Version protected Integer version;
@ManyToOne @JoinColumn(name="ADDR")
protected Address address;
public Integer getEmpId() {
... }
public void setEmpId(Integer id) {
... }
public Address getAddress() {
... }
public void setAddress(Address addr) {
... }
}
// FTEMPLOYEE 表实体
@Entity
public class FTEmployee extends Employee {
// Inherited empId field mapped to FTEMPLOYEE.EMPID
// Inherited version field mapped to FTEMPLOYEE.VERSION
// Inherited address field mapped to FTEMPLOYEE.ADDR fk
// Defaults to FTEMPLOYEE.SALARY
protected Integer salary;
public FTEmployee() {
}
public Integer getSalary() {
... }
public void setSalary(Integer salary) {
... }
}
// FTEMPLOYEE 表实体 并重写父类的属性
@Entity
@Table(name="PT_EMP")
@AssociationOverride(
name="address",
joincolumns=@JoinColumn(name="ADDR_ID"))
public class PartTimeEmployee extends Employee {
// Inherited empId field mapped to PT_EMP.EMPID
// Inherited version field mapped to PT_EMP.VERSION
// address field mapping overridden to PT_EMP.ADDR_ID fk
@Column(name="WAGE")
protected Float hourlyWage;
public PartTimeEmployee() {
}
public Float getHourlyWage() {
... }
public void setHourlyWage(Float wage) {
... }
}
@Embeddable
描述
指定一个类,其实例存储为所属实体的内在部分,并共享该实体的标识。嵌入对象的每个持久属性或字段都映射到实体的数据库表。
通俗一点:指定类为可引用,供其它实体类用@Embedded注解引用使用。
属性
无
例子
Example 1:
@Embeddable public class EmploymentPeriod {
@Temporal(DATE) java.util.Date startDate;
@Temporal(DATE) java.util.Date endDate;
...
}
Example 2:
@Embeddable public class PhoneNumber {
protected String areaCode;
protected String localNumber;
@ManyToOne PhoneServiceProvider provider;
...
}
@Entity public class PhoneServiceProvider {
@Id protected String name;
...
}
Example 3:
@Embeddable public class Address {
protected String street;
protected String city;
protected String state;
@Embedded protected Zipcode zipcode;
}
@Embeddable public class Zipcode {
protected String zip;
protected String plusFour;
}
@Embedded
描述
指定其值为可嵌入类实例的实体的持久字段或属性。可嵌入类必须标注为Embeddable。AttributeOverride、AttributeOverrides、AssociationOverride和AssociationOverrides注解可以用来覆盖可嵌入类声明的或默认的映射。
属性
无
例子
@Embedded
@AttributeOverrides({
@AttributeOverride(name="startDate", column=@Column("EMP_START")),
@AttributeOverride(name="endDate", column=@Column("EMP_END"))
})
public EmploymentPeriod getEmploymentPeriod() {
... }
关联关系注解
@OneToOne
描述
1、 指定与另一个具有一对一的实体关联通常不需要显式指定关联的目标实体,因为通常可以从被引用对象的类型推断出它如果关系是双向的,非拥有方必须使用OneToOne注解的mappedBy元素来指定拥有方的关系字段或属性;
2、 可以在可嵌入类中使用OneToOne注解来指定从可嵌入类到实体类的关系如果关系是双向的,并且包含可嵌入类的实体位于关系的拥有方,则非拥有方必须使用OneToOne注解的mappedBy元素来指定可嵌入类的关系字段或属性必须在mapappedby元素中使用点(“.”)符号语法来指示嵌入属性中的关系属性使用点表示法的每个标识符的值都是各自嵌入字段或属性的名称;
属性
targetEntity:(可空)关联字段的实体类。通常不必指定,框架根据属性类型自动判断。默认void.class。
cascade:(可选)级联的操作权限。PERSIST:级联持久化,REMOVE:级联删除,MERGE:级联更新,DETACH:级联脱管/游离,REFRESH:级联刷新,ALL:包含上述的所有权限
fetch:表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主动获取和延迟加载,默认为 EAGER。
optional:(可选)是否可选关联。如果设置为false,则非null关系必须存在。默认true。
mappedBy:(可选)拥有关联的字段。该元素仅在非拥有方指定。
orphanRemoval:(可选)是否将删除操作应用于已从关系中删除的实体,以及是否将删除操作级联到那些实体。默认false,此属性是针对JavaBean中关联关系的操作,真正的数据库操作还需要 cascade对应的权限。
例子
Example 1: 外键一对一 Customer.CUSTREC_ID 对应CustomerRecord.id
// On Customer class:
@OneToOne(optional=false)
@JoinColumn(
name="CUSTREC_ID", unique=true, nullable=false, updatable=false)
public CustomerRecord getCustomerRecord() {
return customerRecord; }
// On CustomerRecord class:
@OneToOne(optional=false, mappedBy="customerRecord")
public Customer getCustomer() {
return customer; }
Example 2: 级联实体之间相同的主键id
// On Employee class:
@Entity
public class Employee {
@Id Integer id;
@OneToOne @MapsId
EmployeeInfo info;
...
}
// On EmployeeInfo class:
@Entity
public class EmployeeInfo {
@Id Integer id;
...
}
Example 3: 可嵌入类与另一个实体之间的一对一关联。
@Entity
public class Employee {
@Id int id;
@Embedded LocationDetails location;
...
}
@Embeddable
public class LocationDetails {
int officeNumber;
@OneToOne ParkingSpot parkingSpot;
...
}
@Entity
public class ParkingSpot {
@Id int id;
String garage;
@OneToOne(mappedBy="location.parkingSpot") Employee assignedTo;
...
}
@OneToMany
描述
指定一对多的多值关联。
如果使用泛型定义集合来指定元素类型,则不需要指定关联的目标实体类型;否则必须指定目标实体类。如果关系是双向的,则必须使用mappedBy元素来指定作为关系所有者的实体的关系字段或属性。OneToMany注解可以在实体类中包含的可嵌入类中使用,以指定与实体集合的关系。如果关系是双向的,则必须使用mappedBy元素来指定作为关系所有者的实体的关系字段或属性。当集合是java.util.Map、cascade元素和orphanRemoval元素应用于Map值。
属性
参考@OneToOne 有点区别是fetch属性默认是LAZY。
例子
Example 1: 使用范型的一对多
// In Customer class: 一个Customer 拥有多个Order 一个Order拥有一个Customer
@OneToMany(cascade=ALL, mappedBy="customer")
public Set<Order> getOrders() {
return orders; }
In Order class:
@ManyToOne
@JoinColumn(name="CUST_ID", nullable=false)
public Customer getCustomer() {
return customer; }
Example 2: 不使用范型一对多 必须指定targetEntity
// In Customer class:
@OneToMany(targetEntity=com.acme.Order.class, cascade=ALL,
mappedBy="customer")
public Set getOrders() {
return orders; }
// In Order class:
@ManyToOne
@JoinColumn(name="CUST_ID", nullable=false)
public Customer getCustomer() {
return customer; }
Example 3: 使用外键映射的单向一对多关联
// In Customer class:
@OneToMany(orphanRemoval=true)
@JoinColumn(name="CUST_ID") // join column is in table for Order
public Set<Order> getOrders() {
return orders;}
@ManyToOne
描述
指定与另一个具有多对一多的实体类的关联。通常不需要显式指定目标实体,因为通常可以从被引用对象的类型推断出目标实体。如果关系是双向的,非拥有OneToMany实体端必须使用mappedBy元素来指定作为关系所有者的实体的关系字段或属性。ManyToOne注解可以在可嵌入类中用于指定从可嵌入类到实体类的关系。如果关系是双向的,非拥有OneToMany实体端必须使用OneToMany注解的mappedBy元素来指定关系拥有端可嵌入字段或属性的关系字段或属性。必须在mapappedby元素中使用点(“.”)符号语法来指示嵌入属性中的关系属性。使用点表示法的每个标识符的值都是各自嵌入字段或属性的名称。
属性targetEntity:(可空)关联字段的实体类。通常不必指定,框架根据属性类型自动判断。默认void.class。
cascade:(可选)级联的操作权限。PERSIST:级联持久化,REMOVE:级联删除,MERGE:级联更新,DETACH:级联脱管/游离,REFRESH:级联刷新,ALL:包含上述的所有权限
fetch:表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主动获取和延迟加载,默认为 EAGER。
optional:(可选)是否可选关联。如果设置为false,则非null关系必须存在。默认true。
例子
Example 1:
@ManyToOne(optional=false)
@JoinColumn(name="CUST_ID", nullable=false, updatable=false)
public Customer getCustomer() {
return customer; }
Example 2:
@Entity
public class Employee {
@Id int id;
@Embedded JobInfo jobInfo;
...
}
@Embeddable
public class JobInfo {
String jobDescription;
@ManyToOne ProgramManager pm; // Bidirectional
}
@Entity
public class ProgramManager {
@Id int id;
@OneToMany(mappedBy="jobInfo.pm")
Collection<Employee> manages;
}
@ManyToMany
描述
指定多对多的关联。 每一个多对多关联都有两个方面,拥有和不拥有,或相反的方面。连接表是在所属方指定的。如果关联是双向的,任何一方都可以被指定为所属方。如果关系是双向的,非拥有方必须使用ManyToMany注解的mappedBy元素来指定拥有方的关系字段或属性。
中间表在所属方指定。ManyToMany注解可以在实体类中包含的可嵌入类中使用,以指定与实体集合的关系。如果关系是双向的,并且包含可嵌入类的实体是关系的所有者,非所有者一方必须使用ManyToMany注解的mappedBy元素来指定可嵌入类的关系字段或属性。必须在mappedBy元素中使用点(“.”)符号语法来指示嵌入属性中的关系属性。使用点表示法的每个标识符的值都是各自嵌入字段或属性的名称。
属性
targetEntity:(可空)关联字段的实体类。通常不必指定,框架根据属性类型自动判断。默认void.class。
cascade:(可选)级联的操作权限。PERSIST:级联持久化,REMOVE:级联删除,MERGE:级联更新,DETACH:级联脱管/游离,REFRESH:级联刷新,ALL:包含上述的所有权限
fetch:表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主动获取和延迟加载,默认为 LAZY。
mappedBy:(可选)拥有关联的字段。该元素仅在非拥有方指定。
例子
Example 1:范型多对对
// In Customer class:
@ManyToMany
@JoinTable(name="CUST_PHONES")
public Set<PhoneNumber> getPhones() {
return phones; }
// In PhoneNumber class:
@ManyToMany(mappedBy="phones")
public Set<Customer> getCustomers() {
return customers; }
Example 2: 非范型多对多
// In Customer class:
@ManyToMany(targetEntity=com.acme.PhoneNumber.class)
public Set getPhones() {
return phones; }
// In PhoneNumber class:
@ManyToMany(targetEntity=com.acme.Customer.class, mappedBy="phones")
public Set getCustomers() {
return customers; }
Example 3:中间表
// In Customer class:
@ManyToMany
@JoinTable(name="CUST_PHONE",
joinColumns=
@JoinColumn(name="CUST_ID", referencedColumnName="ID"),
inverseJoinColumns=
@JoinColumn(name="PHONE_ID", referencedColumnName="ID")
)
public Set<PhoneNumber> getPhones() {
return phones; }
// In PhoneNumberClass:
@ManyToMany(mappedBy="phones")
public Set<Customer> getCustomers() {
return customers; }
总结
本节主要介绍了 JPA 的定义,以及使用 Spring Data JPA 快速开发,以及实体映射相关的注解。