
22. Data(四)-Spring Data JPA 详解
22. Data(四)-Spring Data JPA 详解
简介
上文Spring Boot 3.x Data(三)-Spring Data JPA 详解 主要介绍了 JPA 相关介绍以及 Spring Boot 集合 Spring Data JPA 快速入门和核心注解。本节将介绍核心的Repository
一、Repository
Spring Data JPA Repository 是你可以定义来访问数据的接口。JPA 查询是根据您的方法名自动创建的。例如,CityRepository接口可以声明findAllByState(String state)方法来查找处于给定状态的所有城市。
Spring Repository 通常从Repository或CrudRepository接口扩展而来。 如果使用自动配置,Repository将从包含主配置类(带@EnableAutoConfiguration或@SpringBootApplication注解的类)的包中搜索。
类结构
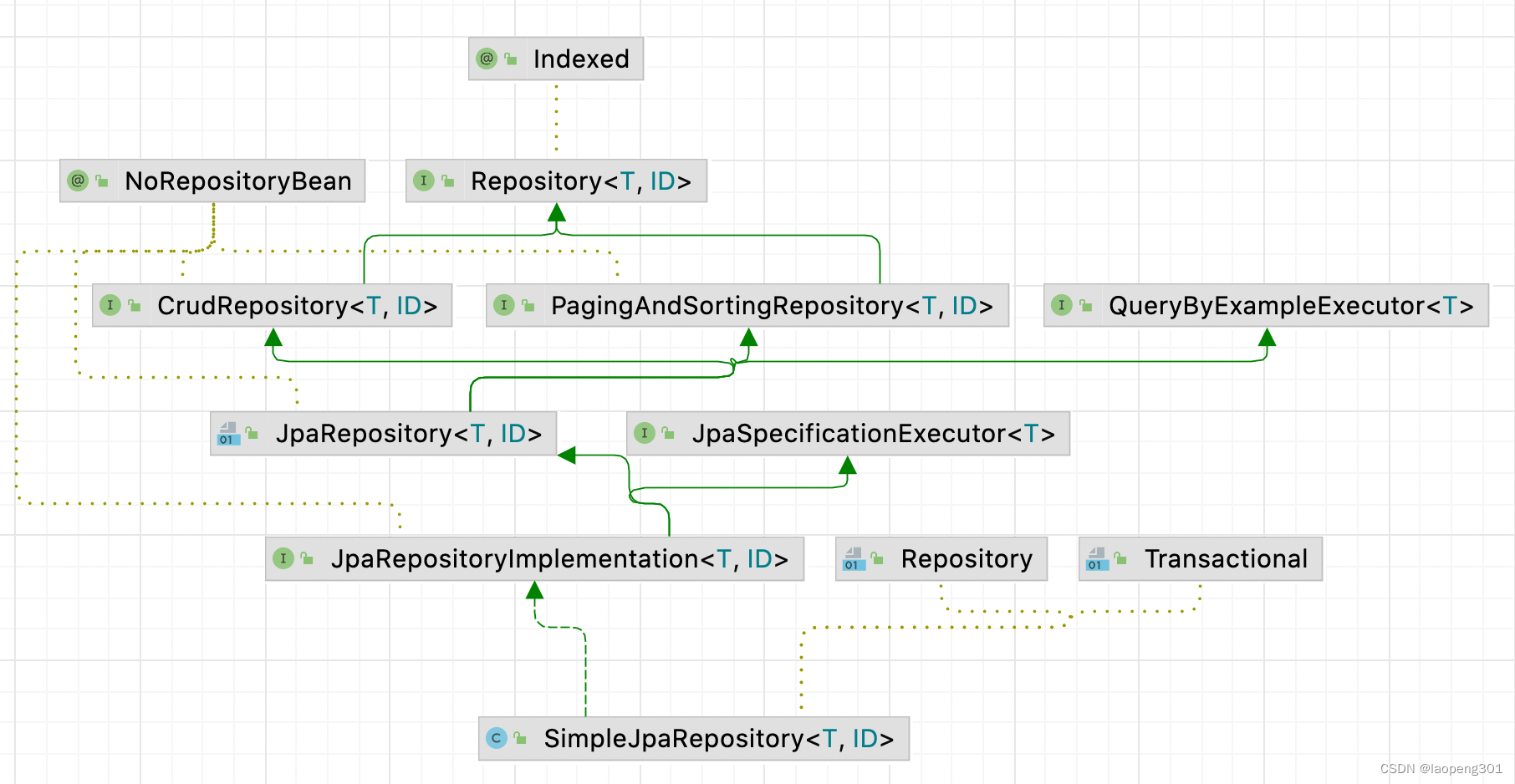
Repository:一个标识接口,表明任何继承它的均为仓库接口类,方便 Spring 自动扫描识别。T:实体类名 ID : 主键类型。Spring 5.0 引入的注解@Indexed ,它可以为 Spring 的模式注解添加索引,以提升应用启动性能。
@Indexed
public interface Repository<T, ID> {
}
CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法 。@NoRepositoryBean:告诉 JPA 不要创建对应接口的bean对象。
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
PagingAndSortingRepository: 继承 Repository,实现了分页排序相关的方法 。
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends Repository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
JpaRepository: 继承 CrudRepository,PagingAndSortingRepository和QueryByExampleExecutor,实现一组 JPA 规范相关的方法。
@NoRepositoryBean
public interface JpaRepository<T, ID> extends CrudRepository<T, ID>, PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
/** @deprecated */
@Deprecated
default void deleteInBatch(Iterable<T> entities) {
this.deleteAllInBatch(entities);
}
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
/** @deprecated */
@Deprecated
T getOne(ID id);
/** @deprecated */
@Deprecated
T getById(ID id);
T getReferenceById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
QueryByExampleExecutor: 不属于Repository体系,接口允许通过实例Example执行动态查询。
public interface QueryByExampleExecutor<T> {
<S extends T> Optional<S> findOne(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
<S extends T> long count(Example<S> example);
<S extends T> boolean exists(Example<S> example);
<S extends T, R> R findBy(Example<S> example, Function<FluentQuery.FetchableFluentQuery<S>, R> queryFunction);
}
JpaSpecificationExecutor:不属于Repository体系,实现一组 JPA Criteria 查询相关的方法 。
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> spec);
List<T> findAll(@Nullable Specification<T> spec);
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
long count(@Nullable Specification<T> spec);
boolean exists(Specification<T> spec);
}
JpaRepositoryImplementation:由JpaRepository实现的SPI接口。
@NoRepositoryBean
public interface JpaRepositoryImplementation<T, ID> extends JpaRepository<T, ID>, JpaSpecificationExecutor<T> {
void setRepositoryMethodMetadata(CrudMethodMetadata crudMethodMetadata);
default void setEscapeCharacter(EscapeCharacter escapeCharacter) {
}
}
SimpleJpaRepository:CrudRepository默认实现。
自定义 Repository
当需要定义自己的Repository接口的时候,可以直接继承JpaRepository,从而获得 SpringBoot Data JPA 为我们内置的多种基本数据操作方法。
@Repository
public interface StudentRepository extends JpaRepository<Student, Integer> {
List<Student> findByGrade(String grade);
}
二、数据操作
1.持久化实体
保存实体可以使用CrudRepository.save(…)方法来执行。它通过使用底层JPA EntityManager持久化或合并给定的实体。如果实体还没有被持久化,Spring Data JPA 通过调用entityManager.persist(…)方法来保存实体。否则,它将调用entityManager.merge(…)方法。
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
//实体状态检测
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
实体生命周期
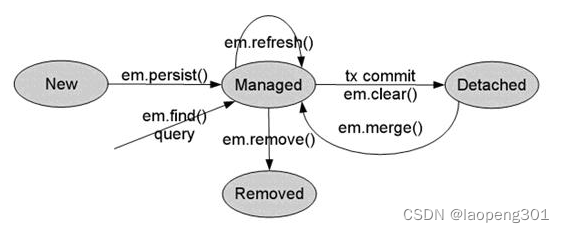
瞬时(New):瞬时对象,刚 New 出来的对象,无id,还未和持久化上下文(Persistence Context)建立关联。托管(Managed):托管对象,有id,已和持久化上下文(Persistence Context)建立关联,对象属性的所有改动均会影响到数据库中对应记录。
- 瞬时对象调用 em.persist()方法之后,对象由瞬时状态转换为托管状态
- 通过 find、get、query 等方法,查询出来的对象为托管状态
- 游离状态的对象调用 em.merge 方法,对象由游离状态转换为托管状态
游离(Datached):游离对象,有id值,但没有和持久化上下文(Persistence Context)建立关联。
- 托管状态对象提交事务之后,对象状态由托管状态转换为游离状态
- 托管状态对象调用 em.clear()方法之后,对象状态由托管状态转换为游离状态
- New 出来的对象,id 赋值之后,也为游离状态
删除(Removed):执行删除方法(em.remove())但未提交事务的对象,有id值,没有和持久化上下文(Persistence Context)建立关联,即将从数据库中删除。
实体状态检测
Spring Data JPA 提供了以下策略来检测一个实体是否是新的:
1、 版本-属性和 Id-属性检测(默认):默认情况下,SpringDataJPA 首先检查是否有非原始类型的版本属性(@Version),如果存在且该属性的值为null,则该实体被认为是新的如果没有这样的版本属性,SpringDataJPA 将检查给定实体的标识符属性(@Id)如果标识符属性为空,则假定该实体是新的否则,它被认为不是新的;
2、 实现Persistable接口:如果一个实体实现了Persistable,SpringDataJPA 将新的检测委托给该实体的isNew(…)方法;
3、 实现EntityInformation接口:你可以通过创建JpaRepositoryFactory的子类并相应地重写getEntityInformation(…)方法来定制在SimpleJpaRepository实现中使用的EntityInformation抽象然后,你必须将JpaRepositoryFactory的自定义实现注册为 Springbean 注意,这很少是有必要的;
对于那些使用手动分配的标识符且没有版本属性的实体,选项1不是一个选项,因为标识符总是非空的。在这种情况下,一个常见的模式是使用一个带有临时标志的通用基类来指示一个新实例,并使用 JPA 生命周期回调来在持久化操作中翻转该标志:
@MappedSuperclass
public abstract class AbstractEntity<ID> implements Persistable<ID> {
@Transient
//声明一个标志来保存新状态。瞬态的,这样它就不会持久化到数据库中。
private boolean isNew = true;
@Override
/**
*返回Persistable.isnew()实现中的标志,以便Spring数据存储库知道是调用EntityManager.persist()还是....merge()。
**/
public boolean isNew() {
return isNew; //2
}
/**
*使用JPA实体回调声明一个方法,以便在存储库调用save(…)或持久化提供程序创建实例之后,切换标志。
**/
@PrePersist //3
@PostLoad
void markNotNew() {
this.isNew = false;
}
// More code…
}
2.查询方法
JPA 模块支持将查询手动声明定义为String或从方法名派生。
方法名派生
public interface UserRepository extends Repository<User, Long> {
List<User> findByEmailAddressAndLastname(String emailAddress, String lastname);
}
我们使用 JPA 标准 API 从这里创建一个查询,但是本质上,这转换为以下查询:select u from User u where u.emailAddress = ?1 and u.lastname = ?2
下表描述了JPA支持的关键字,以及包含该关键字的方法可以转换成什么:
| 关键字 | 示例 | JPQL |
|---|---|---|
Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
LessThan | findByAgeLessThan | … where x.age < ?1 |
LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
After | findByStartDateAfter | … where x.startDate > ?1 |
Before | findByStartDateBefore | … where x.startDate < ?1 |
IsNull, Null | findByAge(Is)Null | … where x.age is null |
IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
Like | findByFirstnameLike | … where x.firstname like ?1 |
NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (参数绑定附加 %) |
EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (参数绑定附加 %) |
Containing | findByFirstnameContaining | … where x.firstname like ?1(参数绑定包含在%中) |
OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
Not | findByLastnameNot | … where x.lastname <> ?1 |
In | findByAgeIn(Collection ages) | … where x.age in ?1| |
NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
True | findByActiveTrue() | … where x.active = true |
False | findByActiveFalse() | … where x.active = false |
IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
In和NotIn也接受Collection的任何子类以及数组或可变参数作为参数。
声明查询
尽管从方法名派生出查询非常方便,但你可能会遇到这样的情况:方法名解析器不支持你想要使用的关键字,或者方法名会变得不必要地难看。因此,你可以通过命名约定使用 JPA 命名查询,或者使用@Query注解你的查询方法。
JPA 命名查询
1、 实体命名查询注解声明:;
@Entity
@NamedQuery(name = "User.findUser", query = "select u from User u where u.id = ?1")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String firstName;
private String lastName;
private String emailAddress;
}
2、 Repository接口声明:;
@Repository
public interface UserRepository extends JpaRepository<User, Integer> {
User findUser(Integer id);
}
3、 测试;
@Bean
public CommandLineRunner userTest(UserRepository userRepository){
return args -> {
logger.info("初始化user");
userRepository.save(new User("KAKA","LUO","LUOKAKA@123.COM"));
logger.info("使用命名查询的方式查询id为1的用户");
userRepository.findUser(1);
};
}

Spring Data 尝试将对这些方法的调用解析为命名查询,从配置的实体类的简单名称开始,然后是用点分隔的方法名称。因此,前面的示例将使用前面定义的命名查询,而不是试图从方法名创建查询。
Query 注解
使用命名查询来为实体声明查询是一种有效的方法,对于少量查询也适用。由于查询本身与运行它们的 Java 方法绑定在一起,你实际上可以通过使用 Spring Data JPA @Query注解直接绑定它们,而不是将它们注解到实体类。这将实体类从特定于持久性的信息中解放出来。
@Repository
public interface UserRepository extends JpaRepository<User, Integer> {
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress(String emailAddress);
}
测试:
User user=userRepository.findByEmailAddress("LUOKAKA@123.COM");
logger.info("使用@Query方式查询用户信息为:"+user.toString());

原生 SQL
@Query("select u from User u where u.emailAddress = ?1")默认使用的是JPQL,如果需要数据库原生语句可以按照如下方式:
@Query(value = "SELECT * FROM USERS WHERE EMAIL_ADDRESS = ?1", nativeQuery = true)
User findByEmailAddress(String emailAddress);
Spring Data JPA 目前不支持原生查询的动态排序, 因为它必须操作实际声明的查询,这对于原生SQL是不可靠的。但是,你可以通过自己指定count查询来使用原生查询进行分页,如下面的示例所示:
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM USERS WHERE LAST_NAME = ?1",
countQuery = "SELECT count(*) FROM USERS WHERE LAST_NAME = ?1",
nativeQuery = true)
Page<User> findByLastname(String lastname, Pageable pageable);
}
排序
排序可以通过提供一个PageRequest或直接使用Sort来完成。Sort的排序实例中实际使用的属性需要匹配你的实体模型,这意味着它们需要解析为查询中使用的属性或别名。JPQL将其定义为状态字段路径表达式。
但是,将Sort与@Query结合使用,可以在Order BY子句中嵌入包含函数的非路径检查的排序,这是可能的,因为排序被附加到给定的查询字符串。Spring Data JPA 拒绝任何包含函数调用的排序,但是你可以使用JpaSort.unsafe添加可能不安全的排序。
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.lastname like ?1%")
List<User> findByAndSort(String lastname, Sort sort);
@Query("select u.id, LENGTH(u.firstname) as fn_len from User u where u.lastname like ?1%")
List<Object[]> findByAsArrayAndSort(String lastname, Sort sort);
}
//指向实体中属性的有效排序表达式
repo.findByAndSort("lannister", Sort.by("firstname"));
//包含函数调用的排序无效。抛出异常。
repo.findByAndSort("stark", Sort.by("LENGTH(firstname)"));
//包含显式不安全顺序的有效排序。
repo.findByAndSort("targaryen", JpaSort.unsafe("LENGTH(firstname)"));
// 指向别名函数的有效排序表达式。
repo.findByAsArrayAndSort("bolton", Sort.by("fn_len"));
使用命名参数
默认情况下,Spring Data JPA 使用基于位置的参数绑定,如上例所述。这使得查询方法在重构参数位置时容易出错。为了解决这个问题,你可以使用@Param注释给一个方法参数一个具体的名称,并在查询中绑定该名称,如下所示的示例:
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.firstname = :firstname or u.lastname = :lastname")
User findByLastnameOrFirstname(@Param("lastname") String lastname,
@Param("firstname") String firstname);
}
使用 SpEL 表达式
从 Spring Data JPA 1.4 版开始,支持在@Query 手动定义查询中使用受限的 SpEL 模板表达式。在运行查询时,将根据一组预定义的变量对这些表达式进行计算。 Spring Data JPA 支持一个名为 entityName 的变量。它的用法是 select x from #{#entityName} x。它插入与给 Repository 关联的实体类型 entityName。
entityName的解析如下:如果实体类在@Entity注解上设置了name属性则使用它。否则使用域类型的简单类名。
下面的例子演示了一个查询字符串中#{#entityName}表达式的用例,在这个用例中,用一个查询方法和一个手动定义的查询来定义一个 Repository 接口:
@Entity
public class User {
@Id
@GeneratedValue
Long id;
String lastname;
}
public interface UserRepository extends JpaRepository<User,Long> {
@Query("select u from #{#entityName} u where u.lastname = ?1")
List<User> findByLastname(String lastname);
}
Modifying Query
前面的所有部分都描述了如何声明查询来访问给定的实体或实体集合。你可以通过在查询方法中标注@Modify来修改只需要参数绑定的查询,如下例所示:
@Modifying
@Query("update User u set u.firstname = ?1 where u.lastname = ?2")
int setFixedFirstnameFor(String firstname, String lastname);
派生删除
:Spring Data JPA 还支持派生的删除查询,让你不必显式声明 JPQL 查询,如下所示:
interface UserRepository extends Repository<User, Long> {
void deleteByRoleId(long roleId);
@Modifying
@Query("delete from User u where u.role.id = ?1")
void deleteInBulkByRoleId(long roleId);
}
尽管deleteByRoleId(…)方法看起来与deleteInBulkByRoleId(…)方法产生的结果基本相同,但就运行方式而言,这两个方法声明之间有一个重要的区别。顾名思义,后一种方法对数据库发出单个JPQL查询(注释中定义的查询)。这意味着即使是当前加载的User实例也不会看到生命周期回调被调用。
为了确保实际调用了生命周期查询,deleteByRoleId(…)的调用会运行一个查询,然后逐个删除返回的实例,这样持久化提供程序就可以对这些实体实际调用@PreRemove回调函数。
实际上,派生的删除查询是运行查询,然后对结果调用CrudRepository.delete(Iterable<User> users)并保持行为与CrudRepository中其他delete(…)方法的实现同步的一种快捷方式。
QueryHints
默认情况下,@NameQuery或@NameNativeQuery完全按照查询String指定的方式执行。使用@QueryHint注解指定供应商特定的 JPA 查询扩展,以提高查询性能和利用供应商的 JPA 持续性提供程序实现中的特定特性。@QueryHing有两个属性,name和value。name指定提示名称,value指定提示的值。
@Entity
@NamedQuery(
name="findAllEmployees",
query="SELECT * FROM EMPLOYEE WHERE MGR=1"
hints={
@QueryHint={
name="toplink.refresh", value="true"}}
)
public class Employee implements Serializable {
...
}
使用@QueryHint 批注自定义查询以利用由 TopLink Essentials 提供的供应商 JPA 扩展:在该示例中,提示确保在执行查询时始终刷新 TopLink 缓存。
在Repository接口中通过@QueryHints注解使用 JPA 查询提示。它提供了一组 JPA @QueryHint注解外加一个布尔标识,默认禁止在分页时需要调用的计数查询上使用查询提示,如下例:
public interface UserRepository extends Repository<User, Long> {
@QueryHints(value = {
@QueryHint(name = "name", value = "value")},
forCounting = false)
Page<User> findByLastname(String lastname, Pageable pageable);
}
配置 Fetch 和 LoadGraphs
JPA2.1 规范引入了对Fetch和LoadGraphs的指定支持,我们也通过@EntityGraph注解支持这些功能。它可以让你引用@NamedEntityGraph定义。可以在实体上使用该注解来配置结果查询的获取方式。 获取的类型(Fetch或Load)可以通过使用@EntityGraph注释上的type属性来配置。
@Entity
@NamedEntityGraph(name = "GroupInfo.detail",
attributeNodes = @NamedAttributeNode("members"))
public class GroupInfo {
// default fetch mode is lazy.
@ManyToMany
List<GroupMember> members = new ArrayList<GroupMember>();
…
}
```java
public interface GroupRepository extends CrudRepository<GroupInfo, String> {
@EntityGraph(value = "GroupInfo.detail", type = EntityGraphType.LOAD)
GroupInfo getByGroupName(String name);
}
@NamedEntityGraph里面会定义若干个@NamedAttributeNode,并且Entity里面还有没在这个NamedEntityGraph里面的),load和fetch对于前者没区别,对于后者有区别,区别是fetch对应加载方式固定为lazy即懒加载,load的加载方式有两种,一个是自己设置的方式加载,另一个是FetchType.EAGER。
还可以使用@EntityGraph定义临时实体图。提供的attributePaths被转换成相应的EntityGraph,而不需要显式地将@NamedEntityGraph添加到你的实体类中,如下面的示例所示:
public interface GroupRepository extends CrudRepository<GroupInfo, String> {
@EntityGraph(attributePaths = {
"members" })
GroupInfo getByGroupName(String name);
}
3.存储过程
JPA2.1 规范通过使用 JPA 标准查询 API 引入了对调用存储过程的支持。新增用于在Repository方法上声明存储过程元数据的@Procedure注解。
新建存储过程:
/;
DROP procedure IF EXISTS plus1inout
/;
CREATE procedure plus1inout (IN arg int, OUT res int)
BEGIN ATOMIC
set res = arg + 1;
END
/;
存储过程的元数据可以通过在实体类型上使用NamedStoredProcedureQuery注解来配置。
@Entity
@NamedStoredProcedureQuery(name = "User.plus1", procedureName = "plus1inout", parameters = {
@StoredProcedureParameter(mode = ParameterMode.IN, name = "arg", type = Integer.class),
@StoredProcedureParameter(mode = ParameterMode.OUT, name = "res", type = Integer.class) })
public class User {
}
注意,@NamedStoredProcedureQuery对存储过程有两个不同的名称。name是 JPA 使用的名称。procedureName是存储过程在数据库中的名称。
可以以多种方式从存储库方法引用存储过程。要调用的存储过程可以通过使用@Procedure注解的value或procedureName属性直接定义。它直接引用数据库中的存储过程,忽略通过@NamedStoredProcedureQuery进行的任何配置。
另外,你也可以指定@NamedStoredProcedureQuery.name属性作为@Procedure.name属性。如果没有配置值、procedureName或name,则使用存储库方法的名称作为name属性。
下面的例子展示了如何引用一个显式映射的过程:
@Procedure("plus1inout")
Integer explicitlyNamedPlus1inout(Integer arg);
下面的示例与前面的示例相同,但使用了procedureName别名:
@Procedure(procedureName = "plus1inout")
Integer callPlus1InOut(Integer arg);
下面的代码同样等价于前两个,但使用的是方法名,而不是显式的注解属性。
@Procedure
Integer plus1inout(@Param("arg") Integer arg);
下面的示例展示了如何通过引用@NamedStoredProcedureQuery.name属性来引用存储过程。
@Procedure(name = "User.plus1IO")
Integer entityAnnotatedCustomNamedProcedurePlus1IO(@Param("arg") Integer arg);
如果被调用的存储过程具有单个输出参数,则该参数可以作为方法的返回值返回。如果在
@NamedStoredProcedureQuery注解中指定了多个out参数,则可以将这些参数作为Map返回,键为@NamedStoredProcedureQuery注解中给出的参数名称。
4.Specification
JPA2 引入了一个标准 API,你可以使用它以编程方式构建查询。通过编写criteria你可以为实体类定义查询的where子句。再退一步,可以将这些标准视为 JPA 标准 API 约束所描述的实体的谓词。
Spring Data JPA 采用了 Eric Evans 的书《域驱动设计》中的规范概念,遵循相同的语义,并提供了一个 API 来定义 JPA 标准 API 中的此类规范。为了支持规范,你可以使用JpaSpecificationExecutor接口扩展你的Repository接口,如下所示:
public interface StudentRepository extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> {
…
}
附加的接口具有允许您以多种方式运行规范的方法。例如,findAll方法返回所有匹配规范的实体,如下面的示例所示:
List<T> findAll(Specification<T> spec);
Specification规范如下:
public interface Specification<T> {
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query,
CriteriaBuilder builder);
}
测试:
studentRepository.findAll((Specification<Student>) (root, query, criteriaBuilder) -> {
return criteriaBuilder.equal(root.get("sex"), 1);
});
select student0_.id as id1_0_, student0_.age as age2_0_, student0_.grade as grade3_0_, student0_.name as name4_0_, student0_.sex as sex5_0_ from tb_student student0_ where student0_.sex=1
多个Specification组合
public class CustomerSpecs {
public static Specification<Customer> isLongTermCustomer() {
return (root, query, builder) -> {
LocalDate date = LocalDate.now().minusYears(2);
return builder.lessThan(root.get(Customer_.createdAt), date);
};
}
public static Specification<Customer> hasSalesOfMoreThan(MonetaryAmount value) {
return (root, query, builder) -> {
// build query here
};
}
}
组合
MonetaryAmount amount = new MonetaryAmount(200.0, Currencies.DOLLAR);
List<Customer> customers = customerRepository.findAll(
isLongTermCustomer().or(hasSalesOfMoreThan(amount)));
5.Example
在 Spring Data JPA 中,你可以使用基于Repository的Example查询,如下面的示例所示:
public interface PersonRepository extends JpaRepository<Person, String> {
… }
public class PersonService {
@Autowired PersonRepository personRepository;
public List<Person> findPeople(Person probe) {
return personRepository.findAll(Example.of(probe));
}
}
6.事物
默认情况下,从SimpleJpaRepository继承的存储库实例上的CRUD方法是事务性的。对于读操作,事务配置readOnly标志设置为true。 所有其他事务都配置了普通的@Transactional,以便应用默认的事务配置。
如果你需要调整在Repository中声明的方法之一的事务配置,请在Repository接口中重新声明该方法,如下所示:
public interface UserRepository extends CrudRepository<User, Long> {
@Override
@Transactional(timeout = 10)
public List<User> findAll();
// Further query method declarations
}
这样做会导致findAll()方法运行超时时间为 10 秒,并且没有readOnly标志。
改变事务行为的另一种方法是使用(通常)覆盖多个Repository的facade或service实现。其目的是为非crud操作定义事务边界。下面的例子展示了如何在多个Repository中使用:
@Service
public class UserManagementImpl implements UserManagement {
private final UserRepository userRepository;
private final RoleRepository roleRepository;
public UserManagementImpl(UserRepository userRepository,
RoleRepository roleRepository) {
this.userRepository = userRepository;
this.roleRepository = roleRepository;
}
@Transactional
public void addRoleToAllUsers(String roleName) {
Role role = roleRepository.findByName(roleName);
for (User user : userRepository.findAll()) {
user.addRole(role);
userRepository.save(user);
}
}
}
查询方法事物
为了让你的查询方法是事务性的,在你定义的Repository接口上使用@Transactional,如下面的示例所示:
@Transactional(readOnly = true)
interface UserRepository extends JpaRepository<User, Long> {
List<User> findByLastname(String lastname);
@Modifying
@Transactional
@Query("delete from User u where u.active = false")
void deleteInactiveUsers();
}
通常,你希望readOnly标志设置为true,因为大多数查询方法只读取数据。与此相反,deleteInactiveUsers()利用@Modify注视并覆盖事务配置。因此,该方法运行时将readOnly标志设置为false。
你可以将事务用于只读查询,并通过设置
readOnly标志将其标记为只读查询。但是,这样做并不会作为检查你是否触发了操作查询(尽管有些数据库会拒绝只读事务中的INSERT和UPDATE语句)。readOnly标志被传播为底层JDBC驱动程序进行性能优化的提示。此外,Spring 对底层 JPA 提供者执行一些优化。例如,当与Hibernate一起使用时,当你将事务配置为readOnly时,刷新模式被设置为NEVER,这导致Hibernate跳过脏检查(对大对象来说是一个显著的改进)。
7.锁
要指定要使用的锁模式,可以在查询方法上使用@Lock注释,示例如下:
interface UserRepository extends Repository<User, Long> {
// Plain query method
@Lock(LockModeType.READ)
List<User> findByLastname(String lastname);
}
这个方法声明导致被触发的查询配备了一个LockModeType为READ。你还可以通过在 Repository 接口中重新声明CRUD方法并添加@Lock注解来为它们定义锁,如下面的示例所示:
interface UserRepository extends Repository<User, Long> {
// Redeclaration of a CRUD method
@Lock(LockModeType.READ)
List<User> findAll();
}
8.审计
审计配置:
Spring Data JPA 附带了一个实体侦听器,可用于触发审计信息的捕获。首先,你必须注册AuditingEntityListener在持久化上下文中的所有实体,如下面的例子所示:
@Entity
@EntityListeners(AuditingEntityListener.class)
public class MyEntity {
}
审计特性依赖
spring-aspects.jar
使用 Java 配置激活审计
@Configuration
@EnableJpaAuditing
class Config {
@Bean
public AuditorAware<AuditableUser> auditorProvider() {
return new AuditorAwareImpl();
}
}
如果你将AuditorAware类型的bean公开给ApplicationContext,审计基础设施将自动获取它并使用它来确定要在实体类型上设置的当前用户。如果你在ApplicationContext中注册了多个实现,你可以通过显式设置@EnableJpaAuditing的auditorAwareRef属性来选择一个要使用的实现。