
Hadoop 异常
Hadoop 面试题
Hadoop 中常问的就三块,第一:分布式存储(HDFS);第二:分布式计算框架(MapReduce);第三:资源调度框架(YARN)。
1.请说下HDFS读写流程;
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
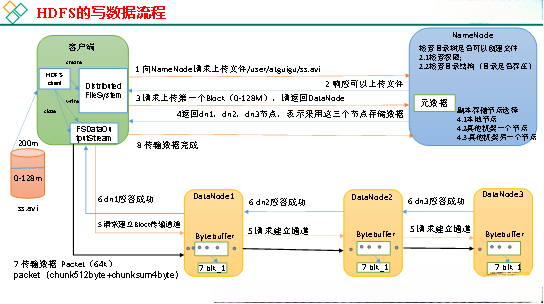
HDFS 写流程:
1、 客户端发送上传请求,并通过RPC与NameNode建立通信NameNode检查用户是否有上传权限,上传的文件在HDFS对应的目录下是否同名如果其中任何一个不满足,就会直接报错如果两者都满足,将向客户端返回一个可以上传的消息;
2、 客户端根据文件大小划分文件,默认为128M,向NameNode发送请求,请求将第一块上传到哪些服务器;
3、 收到请求后,NameNode根据网络拓扑、机架感知和副本机制分配文件,并返回可用DataNode的地址;
4、 接收到地址后,客户端与服务器地址列表中的一个节点进行通信,比如A,本质上是RPC调用建立管道a收到请求后会继续调用B,B会调用C来完成整个管道的建立,并逐步返回给客户端;
5、 客户端开始向A发送第一个块(先从磁盘读取数据,然后放入本地内存缓存),这个块是基于包的(64kb),A收到一个包就会发送;
发送给B,然后B发送给c,A在发送完一个包后会将其放入一个响应队列中等待响应;
6、 数据被分成数据包,依次在流水线上传输在管道反向传输中,逐个发送ack(命令回答正确),最后管道中第一个DataNode节点A向客户端发送pipelineack;7.当一个块传输完成后,客户端请求NameNode再次上传第二个块,NameNode为客户端重新选择三个DataNode;

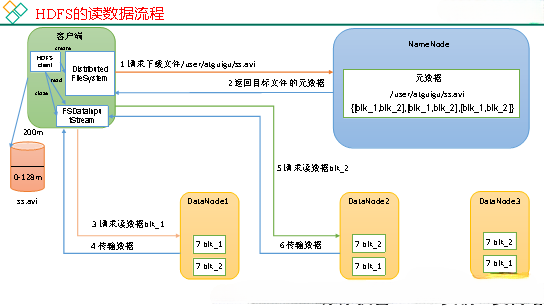
HDFS 读流程:
1、 客户端向NameNode发送RPC请求请求文件块的位置;
2、 NameNode收到请求后会检查用户权限以及是否有这个文件如果它们都匹配,它将根据需要返回部分或全部阻止列表对于每个块,NameNode将返回包含该块副本的DataNode地址;这些返回的DataNode地址会根据集群拓扑得到DataNode到客户端的距离,然后按照两个规则进行排序:网络拓扑中离客户端最近的排在第一位;心跳机制中超上报的DataNode状态陈旧,较低;
3、 客户端选择排名最高的DataNode来读取该块如果客户端本身是DataNode,则直接从本地获取数据(短路读取功能);
4、 在底层,本质是建立一个Socket流(FSDataInputStream),反复调用父类DataInputStream的read方法,直到读取完这个块上的数据;
5、 读取完列表的块后,如果文件读取还没有完成,客户端会继续从NameNode获取下一个块列表;
6、 读取一个块后,将进行校验和验证如果读取DataNode时出现错误,客户端会通知NameNode,然后用块的副本从下一个DataNode继续读取;
7、 读取方法是并行读取块信息,而不是逐个读取;NameNode只返回客户端请求中包含的块的DataNode地址,不返回请求块的数据;
8、 所有读取的块将被合并成一个完整的最终文件;

视频讲解:
https://www.bilibili.com/video/BV1ge411s7UY?p=12
详细读写流程讲解:
https://www.bilibili.com/video/BV12h411t7jB?p=2
2. HDFS 在读取文件的时候,如果其中一个块突然损坏了怎么办
读取DataNode上的数据块后,客户端将验证校验和,即使用HDFS上的原始数据块检查客户端读取的本地数据块。如果检查结果不一致,客户端将通知NameNode,然后继续从下一个DataNode读取块的副本。
3. HDFS 在上传文件的时候,如果其中一个 DataNode 突然挂掉了怎么办
当客户端上传文件时,它与DataNode建立管道。流水线的正方向是客户端向DataNode发送数据包,流水线的反方向是DataNode向客户端发送ack确认,即正确接收数据包后发送确认。
当DataNode突然挂起,客户端无法收到这个DataNode发送的ack确认时,客户端会通知NameNode,NameNode会检查这个块的副本不符合规定,NameNode会通知DataNode复制副本,并会对挂起的DataNode进行离线处理,使其不再参与文件上传和下载。
4. NameNode 在启动的时候会做哪些操作
NameNode数据存储在内存和本地磁盘中,而本地磁盘数据存储在fsimage镜像文件和编辑日志文件中。
首次启动NameNode:
1、 格式化文件系统,以生成fsimage映像文件;
2、 开始命名节点:;
读取fsimage文件并将文件内容加载到内存中。
等待DataNade注册并发送阻止报告
3、 启动DataNode:;
向NameNode注册
发送阻止报告
检查fsimage中记录的块数是否与块报告中的总块数相同。
4、 操作文件系统(创建目录,上传文件,删除文件等):;
·此时内存中已经有文件系统改变的信息,但是磁盘中没有文件系统改变的信息,此时会将这些改变信息写入 edits 文件中,edits 文件中存储的是文件系统元数据改变的信息。
第二次启动NameNode:
1、 读取fsimage并编辑文件;
2、 将fsimage和编辑文件合并成一个新的fsimage文件;
3、 创建一个新的编辑文件,内容最初是空的;
4、 启动DataNode;
5. Secondary NameNode 了解吗,它的工作机制是怎样的
辅助NameNode将NameNode的编辑日志合并到fsimage文件中;其具体工作机制:
1、 辅助NameNode询问NameNode是否需要检查点直接带回NameNode是否检查结果;
2、 辅助NameNode请求执行检查点;;
3、 NameNode滚动正在写入的编辑日志;
4、 在滚动到辅助NameNode之前,复制编辑日志和图像文件;;
5、 次NameNode将编辑日志和图像文件加载到内存中,并将它们合并;
6、 生成新的图像文件fsimage.chkpoint;;
7、 将fsimage.chkpoint复制到NameNode;
8、 NameNode已重命名为fsimagechkpoint作为fsimage;
因此,如果NameNode中的元数据丢失,可以从辅助NameNode中恢复部分元数据信息,但不是全部,因为NameNode正在写入的编辑日志尚未复制到辅助NameNode,并且这部分信息无法恢复。
视频讲解:
https://www.bilibili.com/video/BV1ge411s7UY?p=13
6. Secondary NameNode 不能恢复 NameNode 的全部数据,那如何保证NameNode 数据存储安全
这个问题就要说 NameNode 的高可用了,即 NameNode HA。
如果一个NameNode有一个单点故障,那么配置双NameNode。配置中有两个关键点。一个是保证两个NameNode的元数据信息必须同步,另一个是在一个NameNode挂机后立即补上。
1、 元数据信息同步采用HA方案中的“共享存储”每次写文件时,都需要将日志同步写入共享存储只有这一步成功了,才能决定写文件成功然后,备份节点定期同步来自共享存储的日志,以便在活动和备用之间切换;
1、 ![ ][nbsp3];
img
监控 NameNode 状态采用 zookeeper,两个 NameNode 节点的状态存放在zookeeper 中,另外两个 NameNode 节点分别有一个进程监控程序,实施读取 zookeeper 中有 NameNode 的状态,来判断当前的 NameNode 是不是已经 down 机。如果 Standby 的 NameNode 节点的 ZKFC 发现主节点已经挂掉, 那么就会强制给原本的 Active NameNode 节点发送强制关闭请求,之后将备用的 NameNode 设置为 Active。
7. 在 NameNode HA 中,会出现脑裂问题吗?怎么解决脑裂
精神分裂对于NameNode这种对数据一致性要求非常高的系统来说是灾难性的,数据会出现紊乱,不可恢复。zookeeper社区对这个问题的解决方案是fencing,中文翻译过来就是隔离,即试图隔离旧的活动NameNode,使其无法正常向外界提供服务。
在围栏期间,将执行以下操作:
1、 首先尝试调用这个旧的活动NameNode的HAServiceProtocolRPC接口的transitionToStandby方法,看看是否可以转换到备用状态;
2、 如果transitionToStandby方法调用失败,则实施Hadoop配置文件中预定义的隔离措施Hadoop目前提供了两种隔离措施,它们通常;
选择防护:
SSHFENCE:通过SSH登录目标机器,执行命令fuser杀死相应的进程;
Shell Fence:执行一个用户定义的Shell脚本来隔离相应的进程。
8. 小文件过多会有什么危害,如何避免
Hadoop上大量的HDFS元数据信息都存储在NameNode内存中,所以过多的小文件肯定会淹没NameNode内存。
每个元数据对象占用大约150字节,所以如果有1000万个小文件,每个文件占用一个块,那么NameNode需要大约2G空间。如果存储1亿个文件,NameNode需要20G空间。
解决这个问题的显而易见的方法是合并小文件。可以选择在客户端上传时实现一定的策略先合并,或者使用Hadoop的CombineFileInputFormat<K,V >实现小文件的合并。
9. 请说下 HDFS 的组织架构
1、 Client:客户端;
拆分文档。当上传文件到HDFS时,客户端将文件一个一个地切割成块,然后存储它们。
与NameNode交互以获取文件的位置信息。
与DataNode交互,读取或写入数据
客户端提供一些命令来管理HDFS,如启动和关闭HDFS,访问HDFS目录和内容等。
2、 NameNode:名称节点,也称为主节点,存储数据的元数据信息,但不存储具体的数据;
管理HDFS的命名空间
管理块映射
配置副本策略
处理客户端读写请求
3、 DataNode:数据节点,也称为从节点NameNode给出命令,DataNode执行实际操作;
实际数据块的存储
执行数据块的读/写操作。
4、 辅助NameNode:它不是NameNode的热备盘当NameNode挂掉时,它不能立即替换NameNode并提供服务;
协助NameNode分担工作量。
定期将Fsimage和Edits合并,并将其推送到NameNode。
在紧急情况下,它可以帮助恢复NameNode。
10. 请说下 MR 中 Map Task 的工作机制
简单概述:
通过split将InputFile切割成多个拆分文件,按记录逐行读取内容到map(自己写的处理逻辑的方法)。数据经过map处理后,交给OutputCollect收集器,对结果键进行分区(默认使用hashPartitioner),然后写入buffer。每个map任务都有一个内存缓冲区(循环缓冲区)来存储map的输出结果。当缓冲区快满时,有必要将缓冲区中的数据作为临时文件闪存到磁盘。当整个map任务完成后,将这个map task在磁盘中生成的所有临时文件合并生成最终的正式输出文件,然后等待reduce任务拉取。
详细步骤:
1、 读取数据组件InputFormat(默认为TextInputFormat)会通过getSplits方法对输入目录下的文件进行逻辑切片得到块,尽可能多的块,启动尽可能多的MapTask;
2、 输入文件分块后,由RecordReader对象读取(默认为LineRecordReader),以\n为分隔符,读取一行数据并返回;
<key,value >,Key表示每行第一个字符的偏移值,Value表示该行的文本内容。
3、 读取块并返回<key,value>,进入用户继承的Mapper类,执行用户重写的map函数,在RecordReader读取一行时调用一次;
4、 映射器逻辑完成后,通过context.write为映射器的每个结果收集数据,在collect中,会先进行分区,默认使用HashPartitioner;
5、 接下来,数据将被写入内存内存中的这个区域称为循环缓冲区(默认为100M)缓冲区的作用是批量收集映射器结果,减少磁盘IO的影响我们的键/值对和分区的结果将被写入缓冲区当然,在写之前,键值都被序列化为字节数组;
6、 当循环缓冲区中的数据达到溢出比列(默认为0.8)即80M时,溢出线程启动,需要对这80MB空间中的键进行排序排序是MapReduce模型的默认行为这里的排序也是序列化字节的排序;
7、 合并覆盖的文件,每次覆盖都会在磁盘上生成一个临时文件(写之前判断是否有合并器)如果Mapper的输出结果真的很大,而且有很多次的重写,磁盘上会有几个临时文件当整个数据处理完成后,磁盘中的临时文件被合并,因为只有一个最终文件被写入磁盘,并且为该文件提供了一个索引文件来记录对应于每次减少的数据的偏移量;
11. 请说下 MR 中 Reduce Task 的工作机制
简单描述:
Reduce大致分为复制、排序、归约三个阶段,重点是前两个阶段。
复制阶段包括一个eventFetcher来获取完整的映射列表,Fetcher线程将复制数据。在这个过程中,将启动两个合并线程,inMemoryMerger和onDiskMerger,分别将内存中的数据合并到磁盘中,将磁盘中的数据合并到磁盘中。数据复制完成后,复制阶段也就完成了。
开始排序阶段,主要是执行finalMerge操作,一个纯粹的排序顺序。
段,即完成后的reduce阶段,调用用户定义的reduce函数进行处理。
详细步骤:
1、 Copy阶段:简单地拉取数据Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件(maptask的分区会标识每个maptask属于哪个reducetask,默认reducetask的标识从0开始);
2、 Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘默认情况下第一种形式不启用当内存中的数据量到达一定阈值,就直接启动内存到磁盘的merge与map端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件内存到磁盘的merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件;
3、 合并排序:把分散的数据合并成一个大的数据后,还会再对合并后的数据排序;
4、 对排序后的键值对调用reduce方法:键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中;
12. 请说下 MR 中 Shuffle 阶段
Shuffle阶段依次分为划分、排序、规范、分组四个步骤,其中前三个步骤在map阶段完成,最后一个步骤在reduce阶段完成。
Shuffle是Mapreduce的核心,分布在Mapreduce的map阶段和reduce阶段。一般来说,从Map产生输出到Reduce将数据作为输入的过程称为shuffle。
1、 Collectstage:将MapTask的结果输出到一个默认大小为100M的循环缓冲区,存储key/value、分区信息等;
2、 溢出阶段:当内存中的数据量达到一定阈值时,数据将被写入本地磁盘在将数据写入磁盘之前,需要对数据进行一次排序如果配置了合并器,具有相同分区号和键的数据也将被排序;
3、 在MapTask阶段合并:将所有溢出的临时文件合并一次,以确保;
如果保证一个MapTask,将只生成一个中间数据文件。
4、 复制阶段:ReduceTask启动Fetcher线程,将自身数据的副本复制到已经完成MapTask的节点默认情况下,数据会存储在内存的缓冲区中,当内存的缓冲区达到一定阈值时,数据会被写入磁盘;
5、 在ReduceTask阶段合并:当reduce任务远程复制数据时,将在后台启动两个线程,将数据文件从内存合并到本地;
6、 排序阶段:在合并数据的同时,进行排序操作由于数据在MapTask阶段已经进行了本地排序,ReduceTask只需要保证复制数据的最终整体有效性;
13. Shuffle 阶段的数据压缩机制了解吗
在shuffle 阶段,可以看到数据通过大量的拷贝,从 map 阶段输出的数据,都要通过网络拷贝,发送到 reduce 阶段,这一过程中,涉及到大量的网络 IO,如果数据能够进行压缩,那么数据的发送量就会少得多。
hadoop 当中支持的压缩算法:
gzip、bzip2、LZO、LZ4、Snappy,这几种压缩算法综合压缩和解压缩的速率, 谷歌的 Snappy 是最优的,一般都选择 Snappy 压缩。谷歌出品,必属精品。
14. 在写 MR 时,什么情况下可以使用规约
规约(combiner)是不能够影响任务的运行结果的局部汇总,适用于求和类,不适用于求平均值,如果 reduce 的输入参数类型和输出参数的类型是一样的,则规约的类可以使用 reduce 类,只需要在驱动类中指明规约的类即可。
15. YARN 集群的架构和工作原理知道多少
YARN的基本设计思想是将MapReduce V1中的JobTracker拆分成两个独立的服务:ResourceManager和ApplicationMaster。
ResourceManager负责整个系统的资源管理和分配,ApplicationMaster负责各个应用的管理。
1、 资源管理器:RM是全局资源管理器,负责整个系统的资源管理和分配它主要由两部分组成:调度器和应用管理器;
调度器根据容量、队列和其他约束将系统中的资源分配给正在运行的应用。在保证容量、公平性和服务水平的前提下,优化集群资源的利用率,使所有资源都能得到充分利用。应用管理器负责管理整个系统的所有应用,包括提交应用,与调度器协商资源启动ApplicationMaster,监控ApplicationMaster的运行状态,出现故障时重新启动。
2、 ApplicationMaster:用户提交的申请会对应一个申请主,其主要功能有:;
与RM调度器协商获取资源,以容器表示。
进一步将获得的任务分配给内部任务。
与NM通信以启动/停止任务。
监控所有内部任务的状态,并在任务运行失败时为任务重新申请资源以重启任务。
33、 NodeManager:NodeManager是每个节点的资源和任务管理器一方面,它会定期向RM汇报这个节点的资源使用情况和各个容器的运行状态另一方面,他接收并处理来自AM的容器启动和停止请求;
4、 容器:容器是YARN中的资源抽象,封装了各种资源一个应用程序将被分配一个容器,这个应用程序只能使用这个容器中描述的资源与MapReduceV1中slot的资源封装不同,容器是一个动态的资源划分单元,可以充分利用资源;
16. YARN 的任务提交流程是怎样的
当jobclient向YARN提交应用程序时,YARN会分两个阶段运行应用程序:首先,启动ApplicationMaster第二阶段,ApplicationMaster创建应用程序,为其申请资源,并监控操作直到结束。具体步骤如下:
1、 用户向YARN提交应用程序,并指定ApplicationMaster程序、启动ApplicationMaster的命令和用户程序;
2、 RM将第一个容器分配给这个应用程序,与相应的NM通信,并要求它启动这个容器中的应用程序ApplicationMaster;
3、 应用程序主向RM注册,然后将其拆分为内部子任务,为内部任务申请资源,并监控这些任务的运行,直到结束;
4、 AM通过轮询向RM申请和接收资源;
5、 RM为AM分配资源,并以容器的形式返回;
6、 AM申请资源后,与对应的NM进行通信,要求NM启动任务;
7、 NodeManager为任务设置运行环境,将任务启动命令写入脚本,通过运行脚本启动任务;
8、 每个任务向AM报告其状态和进度,以便在任务失败时可以重新启动;
9、 应用程序完成后,ApplicationMaster退出ResourceManager并关闭自己;
17. YARN 的资源调度三种模型了解吗
在Yarn中有三种调度器可供选择:FIFO调度器、容量调度器和公平调度器。
默认情况下,hadoop的Apache版本使用容量调度程序调度方法。默认情况下,CDH版本使用公平调度程序调度方法。
FIFO调度程序(先来先服务):
FIFO调度程序根据提交的顺序将应用程序排列在一个队列中,这是一个先进先出的队列。在分配资源时,它首先将资源分配给队列中最靠前的应用,然后在最靠前的应用的需求得到满足后将资源分配给下一个应用,以此类推。
FIFO调度程序是最简单和最容易理解的调度程序。它不需要任何配置,但不适合共享集群。大型应用程序可能会占用所有群集资源,导致其他应用程序被阻塞。比如正在执行一个大任务,占用了所有资源,然后提交了一个小任务,这个小任务就会一直被阻塞。
容量调度程序
对于容量调度器,有专门的队列来运行小任务,但是为小任务设置专门的队列会提前占用一定的集群资源,导致大任务的执行时间滞后于FIFO调度器。
公平调度程序(Fair Scheduler):
在公平调度器中,我们不需要提前占用一定的系统资源。公平调度程序将为所有正在运行的作业动态调整系统资源。
例如,当提交第一个大型作业时,只有该作业正在运行。此时,它将获得所有集群资源。当第二个小任务提交后,公平调度器会将一半的资源分配给这个小任务,这样两个任务就可以公平地共享集群资源。
需要注意的是,在公平调度器中,从第二个任务提交到获取资源会有一定的延迟,因为它需要等待第一个任务释放被占用的容器。小任务完成后也会释放自己占用的资源,大任务会获得所有系统资源。最终的结果是,公平调度器既能实现较高的资源利用率,又能保证小任务能及时完成。
1.hdfs 写流程HDFS 读写流程
2.hdfs 读流程HDFS 读写流程
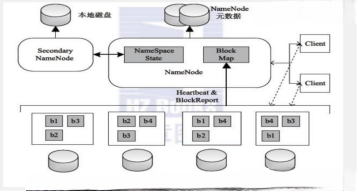
3.hdfs 的体系结构
hdfs 有 namenode、secondraynamenode、datanode 组成。为 n+1 模式
NameNode 负责管理和记录整个文件系统的元数据
DataNode 负责管理用户的文件数据块,文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台 datanode 上,每一个文件块可以有多个副本,并存放在不同的 datanode 上,Datanode 会定期向 Namenode 汇报自身所保存的文件 block 信息,而 namenode 则会负责保持文件的副本数量
HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向 namenode 申请来进行
secondraynamenode 负责合并日志
4. 一个 datanode 宕机,怎么一个流程恢复
Datanode 宕机了后,如果是短暂的宕机,可以实现写好脚本监控,将它启动起来。如果是长时间宕机了,那么 datanode 上的数据应该已经被备份到其他机器了,那这台 datanode 就是一台新的 datanode 了,删除他的所有数据文件和状态文件,重新启动。
5. hadoop 的 namenode 宕机,怎么解决
先分析宕机后的损失,宕机后直接导致 client 无法访问,内存中的元数据丢失,但是硬盘中的元数据应该还存在,如果只是节点挂了,重启即可,如果是机器挂了,重启机器后看节点 是否能重启,不能重启就要找到原因修复了。但是最终的解决方案应该是在设计集群的初期 就考虑到这个问题,做 namenode 的 HA。
6. namenode 对元数据的管理
namenode 对数据的管理采用了三种存储形式: 内存元数据(NameSystem)
磁盘元数据镜像文件(fsimage 镜像)
数据操作日志文件(可通过日志运算出元数据)(edit 日志文件)
7. 元数据的 checkpoint
每隔一段时间,会由 secondary namenode 将 namenode 上积累的所有 edits 和一个最新的
 img
img
fsimage 下载到本地,并加载到内存进行 merge(这个过程称为 checkpoint)
namenode 和 secondary namenode 的工作目录存储结构完全相同,所以,当 namenode 故障退出需要重新恢复时,可以从secondary namenode 的工作目录中将fsimage 拷贝到namenode 的工作目录,以恢复 namenode 的元数据
8. yarn 资源调度流程
Yarn 的资源调度流程
9. hadoop 中 combiner 和 partition 的作用
combiner 是发生在 map 的最后一个阶段,父类就是 Reducer,意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量,缓解网络传输瓶颈,提高 reducer 的执行效率。partition 的主要作用将 map 阶段产生的所有 kv 对分配给不同的 reducer task 处理,可以将reduce 阶段的处理负载进行分摊
10. 用 mapreduce 怎么处理数据倾斜问题?
数据倾斜:map /reduce 程序执行时,reduce 节点大部分执行完毕,但是有一个或者几个reduce 节点运行很慢,导致整个程序的处理时间很长,这是因为某一个 key 的条数比其他key 多很多(有时是百倍或者千倍之多),这条 key 所在的 reduce 节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
(1)局部聚合加全局聚合。
第一次在 map 阶段对那些导致了数据倾斜的 key 加上 1 到 n 的随机前缀,这样本来相同的 key 也会被分到多个 Reducer 中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉 key 的随机前缀,进行全局聚合。
思想:二次 mr,第一次将 key 随机散列到不同 reducer 进行处理达到负载均衡目的。第二次再根据去掉 key 的随机前缀,按原 key 进行 reduce 处理。
这个方法进行两次 mapreduce,性能稍差。
(2)增加 Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将 key 均匀分配到不同 Reducer
11. shuffle 阶段,你怎么理解的
详解MapReduce 执行流程
1、 Mapreduce的map数量和reduce数量是由什么决定的,怎么配置map的数量由输入切片的数量决定,128M切分一个切片,只要是文件也分为一个切片,有多少个切片就有多少个mapTask;
reduce 数量自己配置。
13. MapReduce 优化经验
设置合理的 map 和 reduce 的个数。合理设置 blocksize
避免出现数据倾斜
combine 函数对数据进行压缩
小文件处理优化:事先合并成大文件,combineTextInputformat,在 hdfs 上用 mapreduce 将小文件合并成 SequenceFile 大文件(key:文件名,value:文件内容)
参数优化
14. 分别举例什么情况要使用 combiner,什么情况不使用?
求平均数的时候就不需要用 combiner,因为不会减少 reduce 执行数量。在其他的时候,可以依据情况,使用 combiner,来减少 map 的输出数量,减少拷贝到 reduce 的文件,从而减轻 reduce 的压力,节省网络开销,提升执行效率
15. MR 运行流程解析
详解MapReduce 执行流程
16. 简单描述一下 HDFS 的系统架构,怎么保证数据安全?
 img
img
HDFS 数据安全性如何保证?
存储在HDFS 系统上的文件,会分割成 128M 大小的 block 存储在不同的节点上,block 的副
本数默认 3 份,也可配置成更多份;
第一个副本一般放置在与 client(客户端)所在的同一节点上(若客户端无 datanode,则随机放),第二个副本放置到与第一个副本同一机架的不同节点,第三个副本放到不同机架的datanode 节点,当取用时遵循就近原则;
datanode 已 block 为单位,每 3s 报告心跳状态,做 10min 内不报告心跳状态则 namenode 认为 block 已死掉,namonode 会把其上面的数据备份到其他一个 datanode 节点上,保证数据的副本数量;
datanode 会默认每小时把自己节点上的所有块状态信息报告给 namenode;
采用safemode 模式:datanode 会周期性的报告 block 信息。Namenode 会计算 block 的损坏率,当阀值<0.999f 时系统会进入安全模式,HDFS 只读不写。HDFS 元数据采用 secondaryname备份或者 HA 备份
17. 在通过客户端向 hdfs 中写数据的时候,如果某一台机器宕机了,会怎么处理
在写入的时候不会重新重新分配 datanode。如果写入时,一个 datanode
挂掉,会将已经写入的数据放置到 queue 的顶部,并将挂掉的 datanode 移出pipline,将数据写入到剩余的 datanode,在写入结束后, namenode 会收集datanode 的信息,发现此文件的 replication 没有达到配置的要求(default=3), 然后寻找一个 datanode 保存副本。
18. Hadoop 优化有哪些方面
0)HDFS 小文件影响
(1)影响 NameNode 的寿命,因为文件元数据存储在 NameNode 的内存中
(2)影响计算引擎的任务数量,比如每个小的文件都会生成一个 Map 任务
1)数据输入小文件处理:
(1)) 合并小文件: 对小文件进行归档( Har)、自定义 Inputformat 将小文件存储成
SequenceFile 文件。
(2)采用 ConbinFileInputFormat 来作为输入,解决输入端大量小文件场景。
(3)对于大量小文件 Job,可以开启 JVM 重用。
2)Map 阶段
(1)增大环形缓冲区大小。由 100m 扩大到 200m
(2)增大环形缓冲区溢写的比例。由 80%扩大到 90%
(3)减少对溢写文件的 merge 次数。(10 个文件,一次 20 个 merge)
(4)不影响实际业务的前提下,采用 Combiner 提前合并,减少 I/O。3)Reduce 阶段
(1)合理设置 Map 和 Reduce 数:两个都不能设置太少,也不能设置太多。太少,会导致 Task 等待,延长处理时间;太多,会导致 Map、Reduce 任务间竞争资源,造成处理超时等错误。
(2)设置 Map、Reduce 共存:调整 slowstart.completedmaps 参数,使 Map 运行到一定程度后,Reduce 也开始运行,减少 Reduce 的等待时间。
(3)规避使用 Reduce,因为 Reduce 在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个 Reduce 去 Map 中拿数据的并行数
(5)集群性能可以的前提下,增大 Reduce 端存储数据内存的大小。
4)IO 传输
(1)采用数据压缩的方式,减少网络 IO 的的时间。安装 Snappy 和 LZOP 压缩编码器。
(2)使用 SequenceFile 二进制文件
5)整体
(1)MapTask 默认内存大小为 1G,可以增加 MapTask 内存大小为 4-5g
(2)ReduceTask 默认内存大小为 1G,可以增加 ReduceTask 内存大小为 4-5g
(3)可以增加 MapTask 的 cpu 核数,增加 ReduceTask 的 CPU 核数
(4)增加每个 Container 的 CPU 核数和内存大小
(5)调整每个 Map Task 和 Reduce Task 最大重试次数
19. 大量数据求 topN(写出 mapreduce 的实现思路)
20. 列出正常工作的hadoop 集群中hadoop 都分别启动哪些进程以及他们的作用
1、 NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的;
访问,保存有 metadate。
1、 SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务帮助NN合并editslog,减少NN启动时间;
2、 DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)每个存储数据的节点运行一个datanode守护进程;
3、 ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作每个DataNode;
有一个TaskTracker,它们执行实际工作。5.NodeManager(TaskTracker)执行任务
1、 DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态FC也有选择谁作为ActiveNN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换);
2、 JournalNode高可用情况下存放namenode的editlog文件.21.Hadoop总job和Tasks之间的区别是什么?Job是我们对一个完整的mapreduce程序的抽象封装;
Task 是 job 运行时,每一个处理阶段的具体实例,如 map task,reduce task,maptask 和 reduce
task 都会有多个并发运行的实例22.Hadoop 高可用 HA 模式HDFS 高可用原理:
Hadoop HA(High Available)通过同时配置两个处于 Active/Passive 模式的 Namenode 来解决
上述问题,状态分别是 Active 和 Standby. Standby Namenode 作为热备份,从而允许在机器发生故障时能够快速进行故障转移,同时在日常维护的时候使用优雅的方式进行 Namenode 切换。Namenode 只能配置一主一备,不能多于两个 Namenode。
主Namenode 处理所有的操作请求(读写),而 Standby 只是作为 slave,维护尽可能同步的状态,使得故障时能够快速切换到 Standby。为了使 Standby Namenode 与 Active Namenode 数据保持同步,两个 Namenode 都与一组 Journal Node 进行通信。当主 Namenode 进行任务
的namespace 操作时,都会确保持久会修改日志到 Journal Node 节点中。Standby Namenode
持续监控这些 edit,当监测到变化时,将这些修改同步到自己的 namespace。
当进行故障转移时,Standby 在成为 Active Namenode 之前,会确保自己已经读取了 Journal Node 中的所有 edit 日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode 需要维护最新的 Block 位置信息,即每个 Block 副本存放在集群中的哪些节点上。为了达到这一点,Datanode 同时配置主备两个Namenode,并同时发送 Block 报告和心跳到两台 Namenode。
确保任何时刻只有一个 Namenode 处于 Active 状态非常重要,否则可能出现数据丢失或者数据损坏。当两台 Namenode 都认为自己的 Active Namenode 时,会同时尝试写入数据(不会再去检测和同步数据)。为了防止这种脑裂现象,Journal Nodes 只允许一个 Namenode 写入数据,内部通过维护 epoch 数来控制,从而安全地进行故障转移。
23. 简要描述安装配置一个 hadoop 集群的步骤
l使用 root 账户登录。
l修改 IP。
l修改 Host 主机名。
l配置 SSH 免密码登录。
l关闭防火墙。
l安装 JDK。
l上传解压 Hadoop 安装包。
l配置 Hadoop 的 核 心 配 置 文 件 hadoop-evn.sh , core-site.xml , mapred-site.xml ,
hdfs-site.xml,yarn-site.xml
l配置 hadoop 环境变量
l 格式化 hdfs # bin/hadoop namenode -format
l启动节点 start-all.sh
24. fsimage 和 edit 的区别
fsimage:filesystem image 的简写,文件镜像。
客户端修改文件时候,先更新内存中的 metadata 信息,只有当对文件操作成功的时候,才会写到 editlog。
fsimage 是文件 meta 信息的持久化的检查点。secondary namenode 会定期的将 fsimage 和
editlog 合并 dump 成新的 fsimage
25. yarn 的三大调度策略
lFIFO Scheduler 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再 给下一个分配,以此类推。
lCapacity(容量)调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用 FIFO 调度器时的时间。
l在Fair(公平)调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
26. hadoop 的 shell 命令用的多吗?,说出一些常用的
l-ls
l-put
l-get
l-getmerge
l-mkdir
l-rm
27. 用 mr 实现用户 pv 的 top10?
map输入数据,将数据转换成(用户,访问次数)的键值对,然后 reduce 端实现聚合,并且将结果写入用户、访问次数的实体类,并且实现排序, 最后的结果做一个 top10 的筛选
28. 一个文件只有一行,但是这行有 100G 大小,mr 会不会切分,我们应该怎么解决
重写inputformat
29. hdfs HA 机制, 一台 namenode 宕机了, joualnode , namenode , edit.log fsimage 的 变 化
HDFS HA 机制 及 Secondary NameNode 详解
30、 Mapreduce执行流程说一下?;
详解MapReduce 执行流程
1、 Shulffle过程瓶颈在哪里,你会怎么解决?;
2、 详解MapReduce执行流程;
1.2.1 Hadoop常用端口号
Ødfs.namenode.http-address:50070
Ødfs.datanode.http-address:50075
ØSecondaryNameNode辅助名称节点端口号:50090
Ødfs.datanode.address:50010
Øfs.defaultFS:8020 或者9000
Øyarn.resourcemanager.webapp.address:8088
Ø历史服务器web访问端口:19888
1.2.2 Hadoop配置文件以及简单的Hadoop集群搭建
(1)配置文件:
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
hadoop-env.sh、yarn-env.sh、mapred-env.sh、slaves
(2)简单的集群搭建过程:
JDK安装
配置SSH免密登录
配置hadoop核心文件:
格式化namenode
1.2.3 HDFS读流程和写流程
略
1.2.4 MapReduce的Shuffle过程及Hadoop优化(包括:压缩、小文件、集群优化)
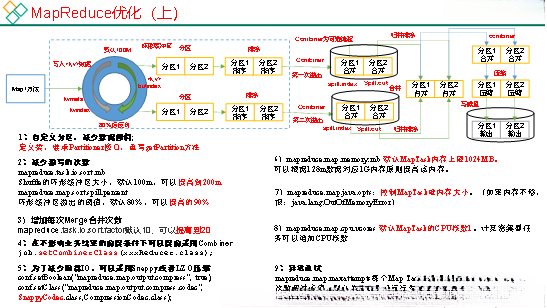
一、Shuffle机制
1)Map方法之后Reduce方法之前这段处理过程叫Shuffle
2)Map方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢写;溢写前对数据进行排序,排序按照对key的索引进行字典顺序排序,排序的手段快排;溢写产生大量溢写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待Reduce端拉取。
3)每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入Reduce方法前,可以对数据进行分组操作。
二、Hadoop优化
0)HDFS小文件影响
(1)影响NameNode的寿命,因为文件元数据存储在NameNode的内存中
(2)影响计算引擎的任务数量,比如每个小的文件都会生成一个Map任务
1)数据输入小文件处理:
(1)合并小文件:对小文件进行归档(Har)、自定义Inputformat将小文件存储成SequenceFile文件。
(2)采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景。
(3)对于大量小文件Job,可以开启JVM重用。
2)Map阶段
(1)增大环形缓冲区大小。由100m扩大到200m
(2)增大环形缓冲区溢写的比例。由80%扩大到90%
(3)减少对溢写文件的merge次数。(10个文件,一次20个merge)
(4)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O。
3)Reduce阶段
(1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
(2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个Reduce去Map中拿数据的并行数
(5)集群性能可以的前提下,增大Reduce端存储数据内存的大小。
4)IO传输
(1)采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
(2)使用SequenceFile二进制文件
5)整体
(1)MapTask默认内存大小为1G,可以增加MapTask内存大小为4-5g
(2)ReduceTask默认内存大小为1G,可以增加ReduceTask内存大小为4-5g
(3)可以增加MapTask的cpu核数,增加ReduceTask的CPU核数
(4)增加每个Container的CPU核数和内存大小
(5)调整每个Map Task和Reduce Task最大重试次数
三、压缩
| 压缩格式 | Hadoop自带? | 算法 | 文件扩展名 | 支持切分 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
提示:如果面试过程问起,我们一般回答压缩方式为Snappy,特点速度快,缺点无法切分(可以回答在链式MR中,Reduce端输出使用bzip2压缩,以便后续的map任务对数据进行split)
四、切片机制
1)简单地按照文件的内容长度进行切片
2)切片大小,默认等于Block大小
3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
提示:切片大小公式:max(0,min(Long_max,blockSize))
1.2.5 Yarn的Job提交流程
略
1.2.6 Yarn的默认调度器、调度器分类、以及他们之间的区别
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Hadoop2.7.2默认的资源调度器是 容量调度器
2)区别:
FIFO调度器:先进先出,同一时间队列中只有一个任务在执行。
容量调度器:多队列;每个队列内部先进先出,同一时间队列中只有一个任务在执行。队列的并行度为队列的个数。
公平调度器:多队列;每个队列内部按照缺额大小分配资源启动任务,同一时间队列中有多个任务执行。队列的并行度大于等于队列的个数。
3)一定要强调生产环境中不是使用的FifoScheduler,面试的时侯会发现候选人大概了解这几种调度器的区别,但是问在生产环境用哪种,却说使用的FifoScheduler(企业生产环境一定不会用这个调度的)
1.2.7 项目经验之LZO压缩
Hadoop默认不支持LZO压缩,如果需要支持LZO压缩,需要添加jar包,并在hadoop的cores-site.xml文件中添加相关压缩配置。
1.2.8 Hadoop参数调优
1)在hdfs-site.xml文件中配置多目录,最好提前配置好,否则更改目录需要重新启动集群
2)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置为60
3)服务器节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。yarn.nodemanager.resource.memory-mb
4)单个任务可申请的最多物理内存量,默认是8192(MB)。yarn.scheduler.maximum-allocation-mb
1.2.9 项目经验之基准测试
搭建完Hadoop集群后需要对HDFS读写性能和MR计算能力测试。测试jar包在hadoop的share文件夹下。
1.2.10 Hadoop宕机
1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
1.2.11 Hadoop解决数据倾斜方法
*1\*)提前在map进行combine,减少传输的数据量\
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key 大量分布在不同的mapper的时候,这种方法就不是很有效了。
*2\*)导致数据倾斜的key 大量分布在不同的mapper\
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度 JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
1.2.12 集群资源分配参数(项目中遇到的问题)
集群有30台机器,跑mr任务的时候发现5个map任务全都分配到了同一台机器上,这个可能是由于什么原因导致的吗?
解决方案:yarn.scheduler.fair.assignmultiple 这个参数 默认是开的,需要关掉
https://blog.csdn.net/leone911/article/details/51605172
1.2.1 Hadoop常用端口号
| hadoop2.x | Hadoop3.x | |
|---|---|---|
| 访问HDFS端口 | 50070 | 9870 |
| 访问MR执行情况端口 | 8088 | 8088 |
| 历史服务器 | 19888 | 19888 |
| 客户端访问集群端口 | 9000 | 8020 |
1.2.2 Hadoop配置文件以及简单的Hadoop集群搭建
(1)配置文件:
Hadoop2.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml slaves
Hadoop3.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml workers
(2)简单的集群搭建过程:
JDK安装
配置SSH免密登录
配置hadoop核心文件
格式化namenode
1.2.3 HDFS读流程和写流程

 img
img
1.2.4 HDFS小文件处理
1)会有什么影响
(1)存储层面:
1个文件块,占用namenode多大内存150字节
1亿个小文件*150字节
1个文件块 * 150字节
128G能存储多少文件块? 128 * 102410241024byte/150字节 = 9亿文件块
(2)计算层面:
每个小文件都会起到一个MapTask,占用了大量计算资源
2)怎么解决
(1)采用har归档方式,将小文件归档
(2)采用CombineTextInputFormat
(3)有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
<description>How many tasks to run per jvm,if set to -1 ,there is no limit</description>
</property>
1.2.5 HDFS的NameNode内存
1)Hadoop2.x系列,配置NameNode默认2000m
2)Hadoop3.x系列,配置NameNode内存是动态分配的
NameNode内存最小值1G,每增加100万个block,增加1G内存。
1.2.6 NameNode心跳并发配置
 img
img
企业经验:dfs.namenode.handler.count= ,比如集群规模(DataNode台数)为3台时,此参数设置为21。可通过简单的python代码计算该值,代码如下。
,比如集群规模(DataNode台数)为3台时,此参数设置为21。可通过简单的python代码计算该值,代码如下。
1.2.7 纠删码原理
CPU资源换存储空间。
 img
img
1.2.8 异构存储(冷热数据分离)
 img
img  img
img
1.2.9 Shuffle及优化
1、Shuffle过程
 img
img 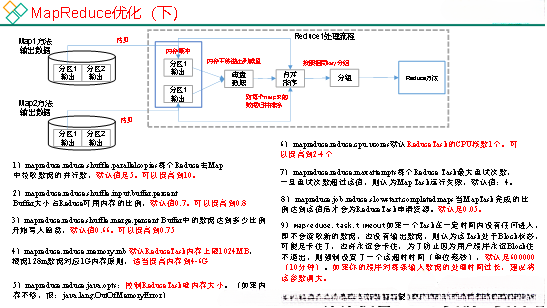 img
img
2、优化
1)Map阶段
(1)增大环形缓冲区大小。由100m扩大到200m
(2)增大环形缓冲区溢写的比例。由80%扩大到90%
(3)减少对溢写文件的merge次数。(10个文件,一次20个merge)
(4)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O。
2)Reduce阶段
(1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
(2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个Reduce去Map中拿数据的并行数
(5)集群性能可以的前提下,增大Reduce端存储数据内存的大小。
3)IO传输
采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
压缩:
(1)map输入端主要考虑数据量大小和切片,支持切片的有Bzip2、LZO。注意:LZO要想支持切片必须创建索引;
(2)map输出端主要考虑速度,速度快的snappy、LZO;
(3)reduce输出端主要看具体需求,例如作为下一个mr输入需要考虑切片,永久保存考虑压缩率比较大的gzip。
4)整体
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G内存左右,yarn.nodemanager.resource.memory-mb。
(2)单容器默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,yarn.scheduler.maximum-allocation-mb。
(3)mapreduce.map.memory.mb :控制分配给MapTask内存上限,如果超过会kill掉进程(报:Container is running beyond physical memory limits. Current usage:565MB of512MB physical memory used;Killing Container)。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加MapTask内存,最大可以增加到4-5g。
(4)mapreduce.reduce.memory.mb:控制分配给ReduceTask内存上限。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加ReduceTask内存大小为4-5g。
(5)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(6)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(7)可以增加MapTask的CPU核数,增加ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml文件中配置多目录(多磁盘)
1.2.10 Yarn工作机制
 img
img 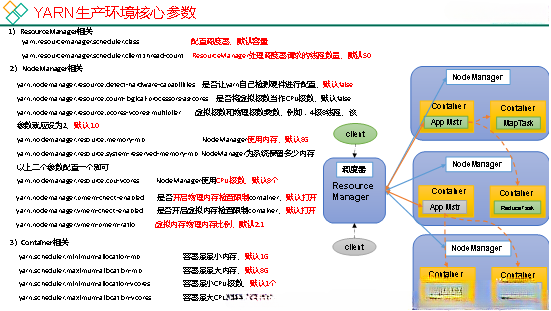 img
img
1.2.11 Yarn调度器
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。
2)区别:
FIFO调度器支持单队列 、先进先出 生产环境不会用。
容量调度器支持多队列。队列资源分配,优先选择资源占用率最低的队列分配资源;作业资源分配,按照作业的优先级和提交时间顺序分配资源;容器资源分配,本地原则(同一节点/同一机架/不同节点不同机架)
公平调度器支持多队列,保证每个任务公平享有队列资源。资源不够时可以按照缺额分配。
3)在生产环境下怎么选择?
大厂:如果对并发度要求比较高,选择公平,要求服务器性能必须OK;
中小公司,集群服务器资源不太充裕选择容量。
4)在生产环境怎么创建队列?
(1)调度器默认就1个default队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
(3)按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
5)创建多队列的好处?
(1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
(2)实现任务的**降级\使用,特殊时期保证重要的任务队列资源充足。
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
1.2.12 项目经验之基准测试
搭建完Hadoop集群后需要对HDFS读写性能和MR计算能力测试。测试jar包在hadoop的share文件夹下。
集群总吞吐量 = 带宽*集群节点个数/副本数
例如:100m/s * 10台/ 3= 333m/s
注意:如果测试数据在本地,那副本数-1。因为这个副本不占集群吞吐量。如果数据在集群外,向该集群上传,需要占用带宽。本公式就不用减1。
1.2.13 Hadoop宕机
1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2)如果写入文件过快造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。例如,可以调整Flume每批次拉取数据量的大小参数batchsize。
1.2.14 Hadoop解决数据倾斜方法
1)提前在map进行combine,减少传输的数据量\
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
2)导致数据倾斜的key 大量分布在不同的mapper\
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度 JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer